Paper: All are Worth Words: A ViT Backbone for Diffusion Models
Code: https://github.com/baofff/U-ViT
本文介绍本组与清华大学朱军教授课题组以及北京智源研究院曹越研究员的合作工作:U-ViT: A ViT Backbone for Diffusion Models
概括
最近,扩散概率模型(diffusion model)在图像生成领域大红大紫,出现了stable-diffusion,Imagen等一系列杰出的工作。扩散概率模型从2015年首次提出至今, 在概率建模方面取得了许多进展,其主干网络也得到了许多改进,从2015年Deep Unsupervised Learning using Nonequilibrium Thermodynamics一文的MLP,到2019年Song Yang在Generative Modeling by Estimating Gradients of the Data Distribution 一文中首次使用U-Net建模score-based model (即diffusion model),后续DDPM ,ADM ,Imagen 等许多工作对U-Net进行了一系列改进。目前,绝大多数扩散概率模型的论文依然使用U-Net作为主干网络。
于此同时,在自然语言处理,以及计算机视觉领域,Transformer架构都展现出大杀四方的特质,不仅在各项任务上取得了很好的效果,也能很好的扩展到多模态学习上。基于这样的背景,U-ViT应运而生。U-ViT将扩散概率模型和Transformer结合,主要展现了以下两类能力:
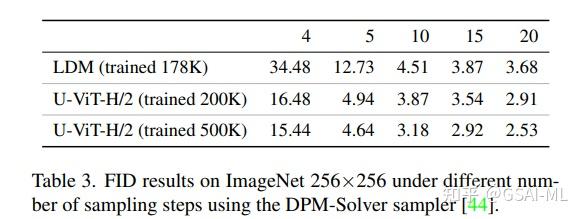
图像生成的SOTA FID 分数
多模态数据的融合
目前,U-ViT已经被CVPR2023接收。
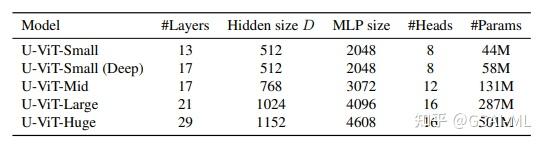
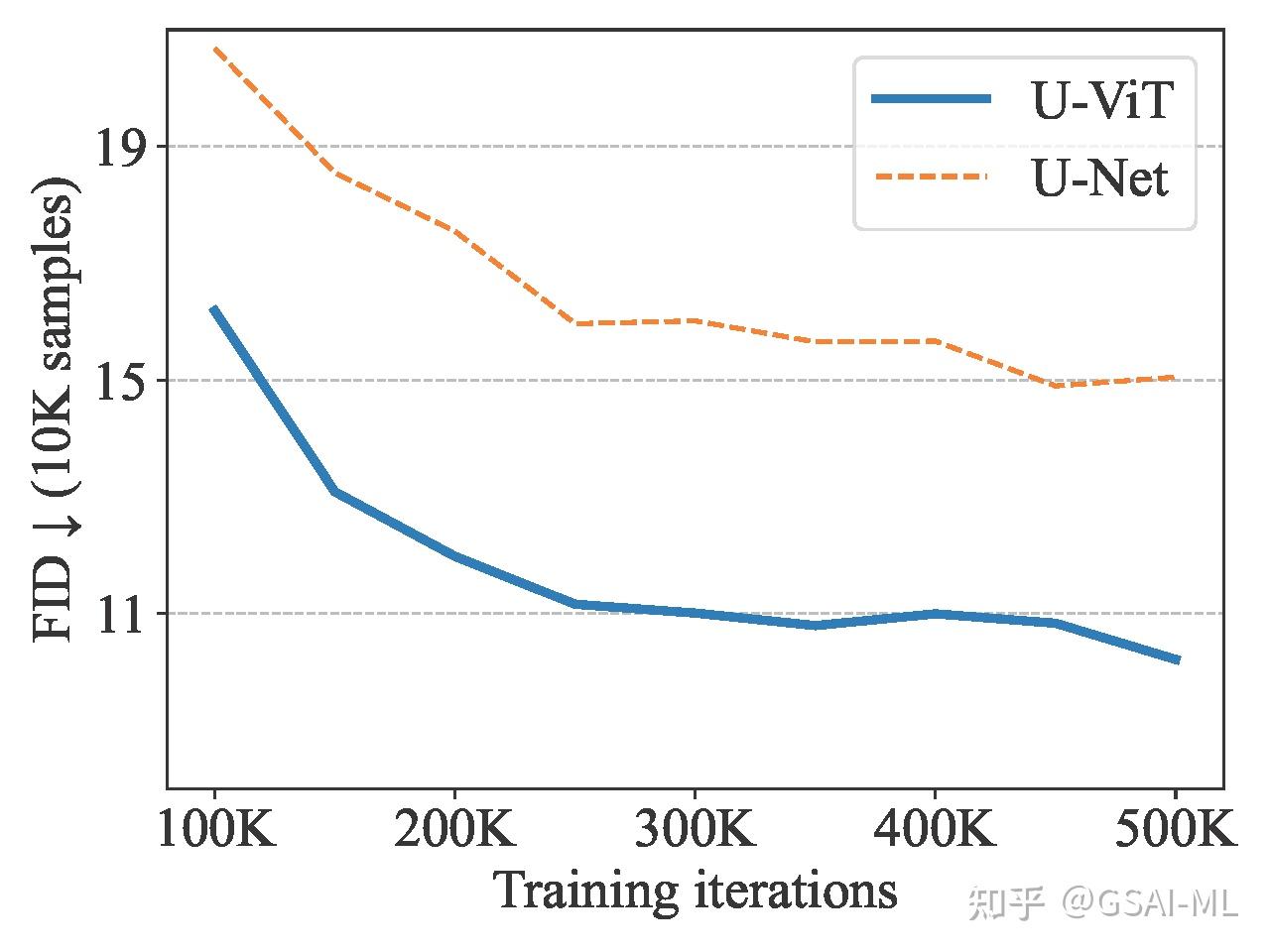
U-ViT网络结构
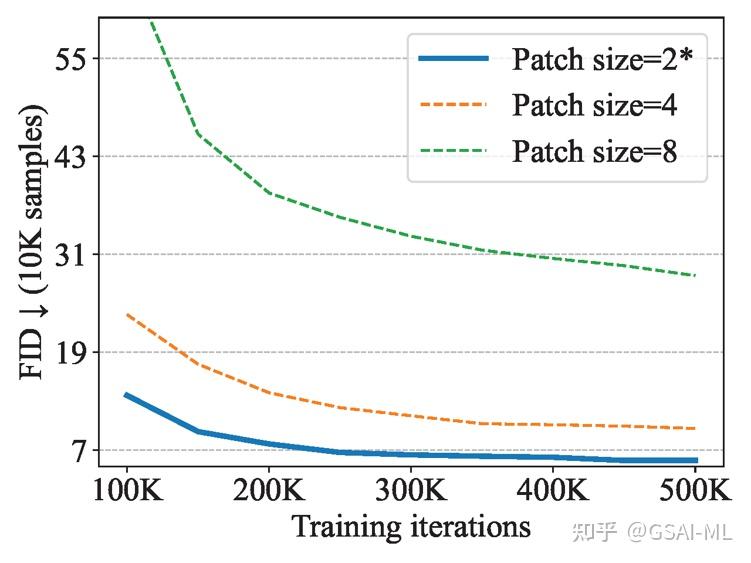
如上图所示,U-ViT延续了ViT的方法,将带噪图片划分为多个patch之后,将时间t,条件c,和图像patch视作token输入到Transformer block,同时在网络浅层和深层之间引入long skip connection。
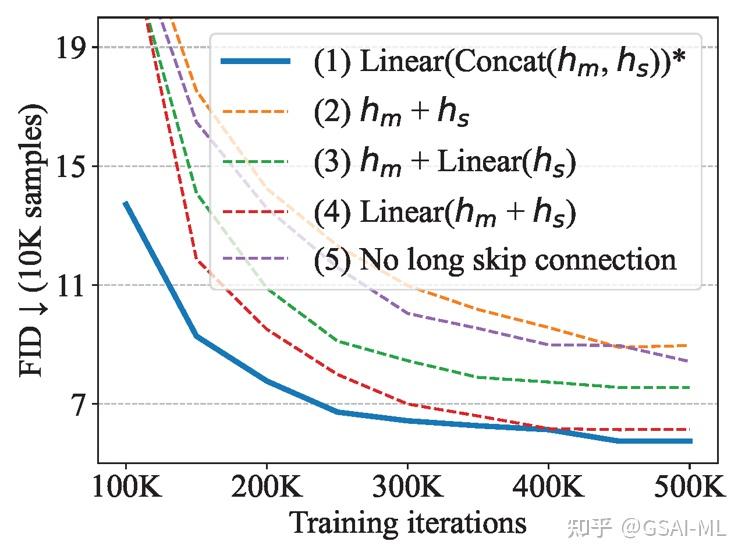
Long skip connection
\begin{array}{|c|c|c|c|c|c|c|} \hline Data & Model & Params(M) & Flops(G) & Batch Size & Training Iteration & Fid \\ \hline ImageNet256 (Latent Diffusion) & U-ViT-H/2 & 501 & 133 & 1024 & 50k & 2.29 \\ \hline ImageNet256 (Latent Diffusion) & DiT-XL/2 & 675 & 118 & 256 & 700k & 2.27 \\ \hline \end{array}
欢迎阅读我们的论文 All are Worth Words: A ViT Backbone for Diffusion Models
作者列表:鲍凡,聂燊,薛凯文,曹越,李崇轩,苏航,朱军 PS: 转载请注明出处



 发表于 2023-7-17 10:41:27
发表于 2023-7-17 10:41:27