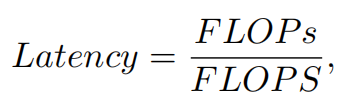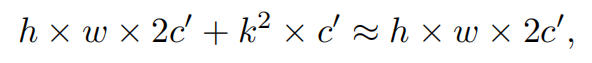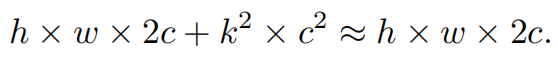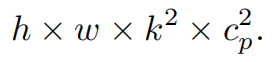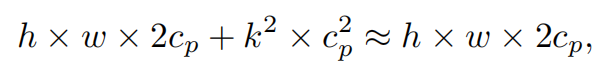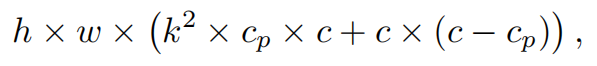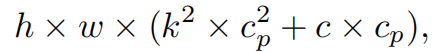3
5
11
新手上路
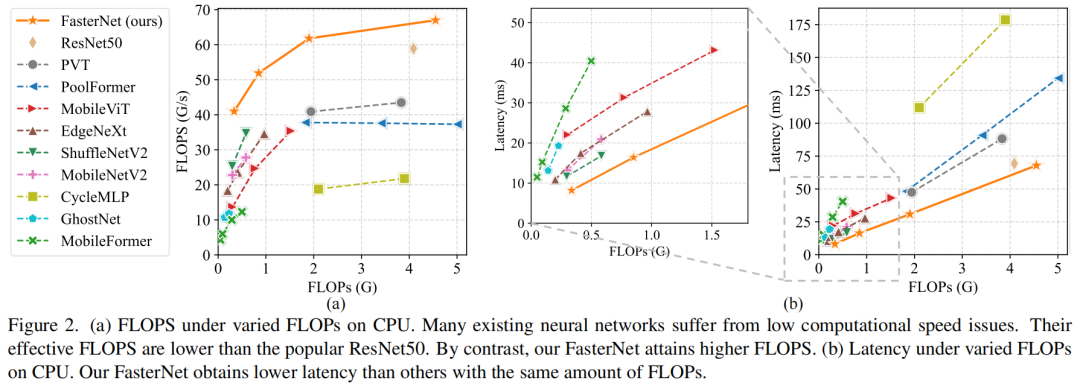
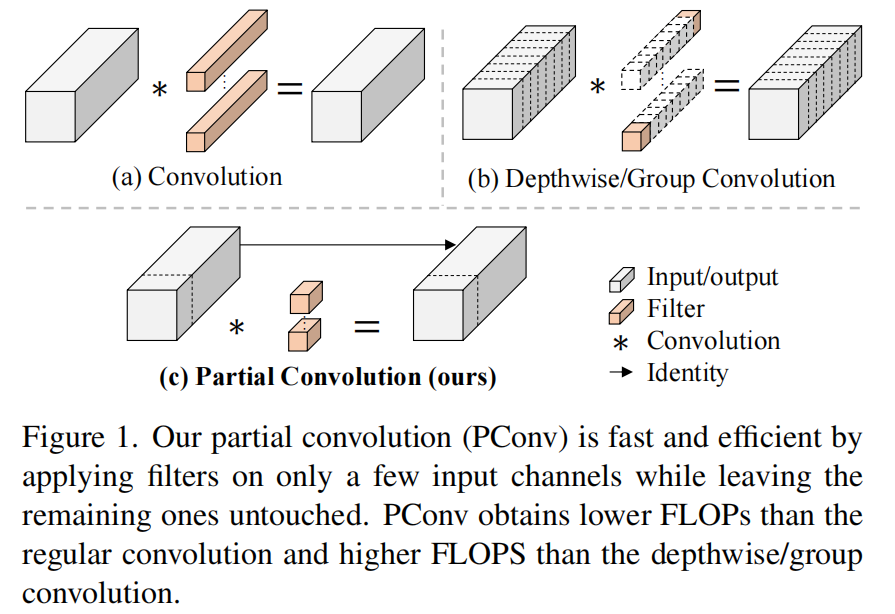
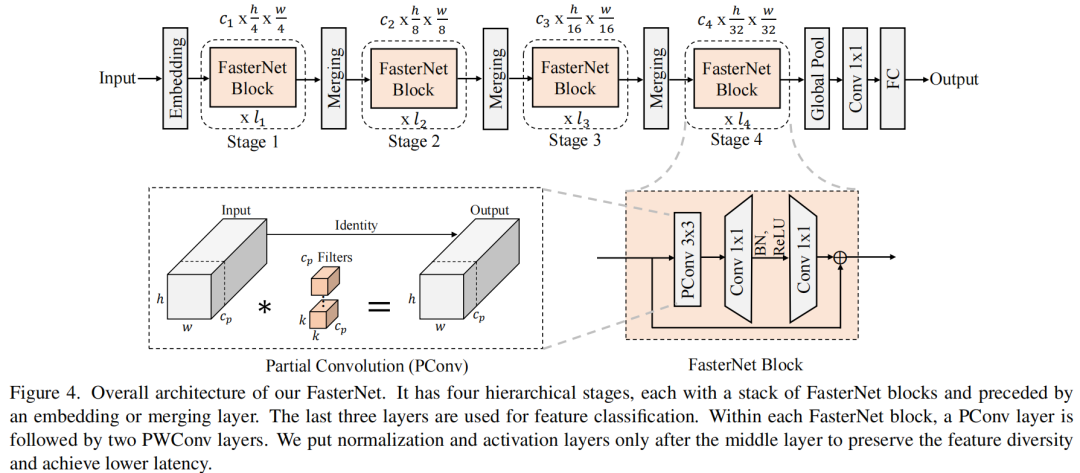
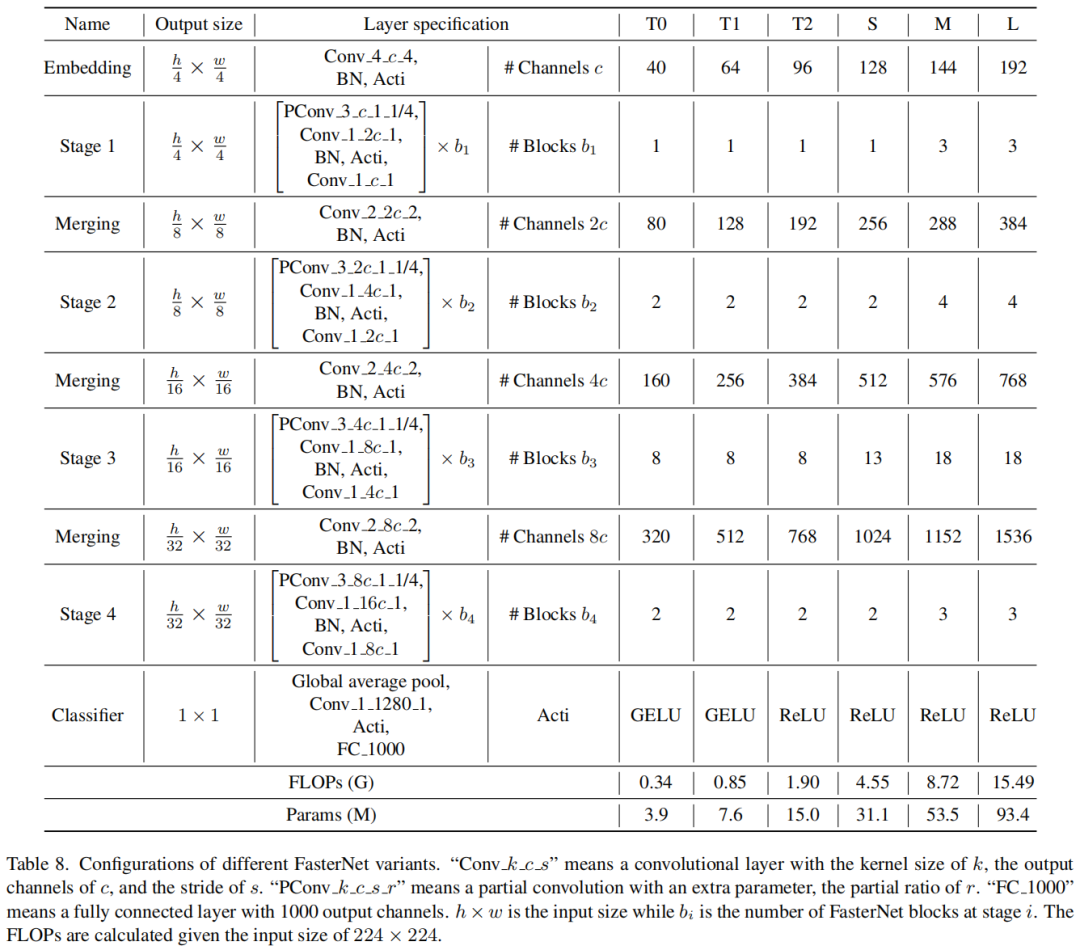
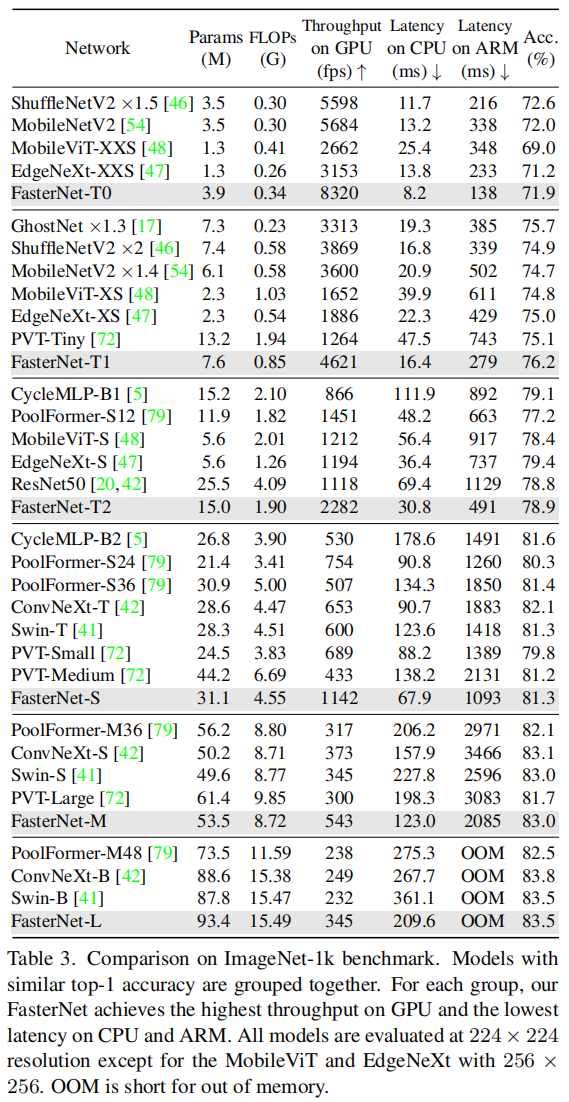
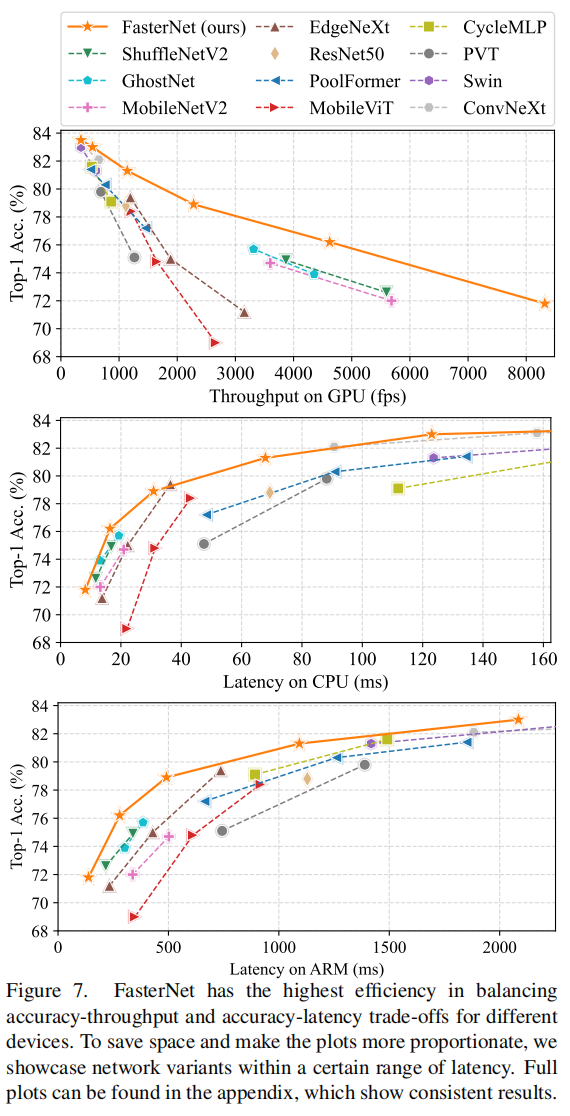
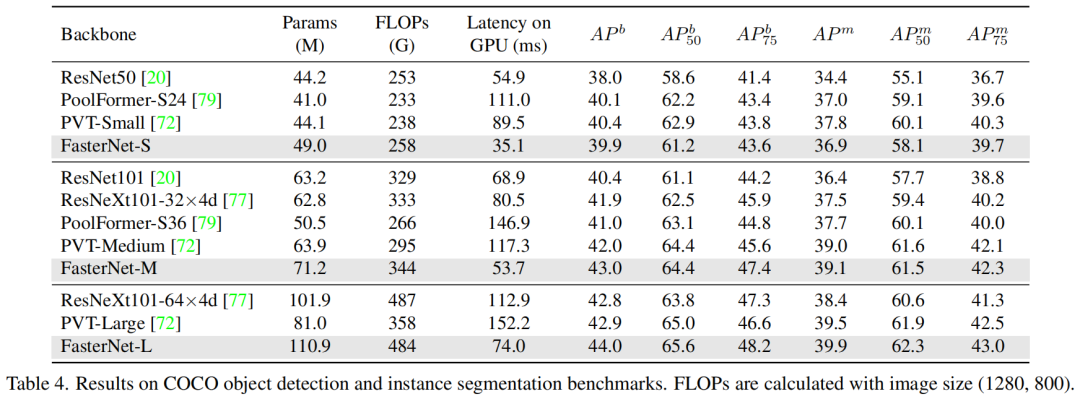
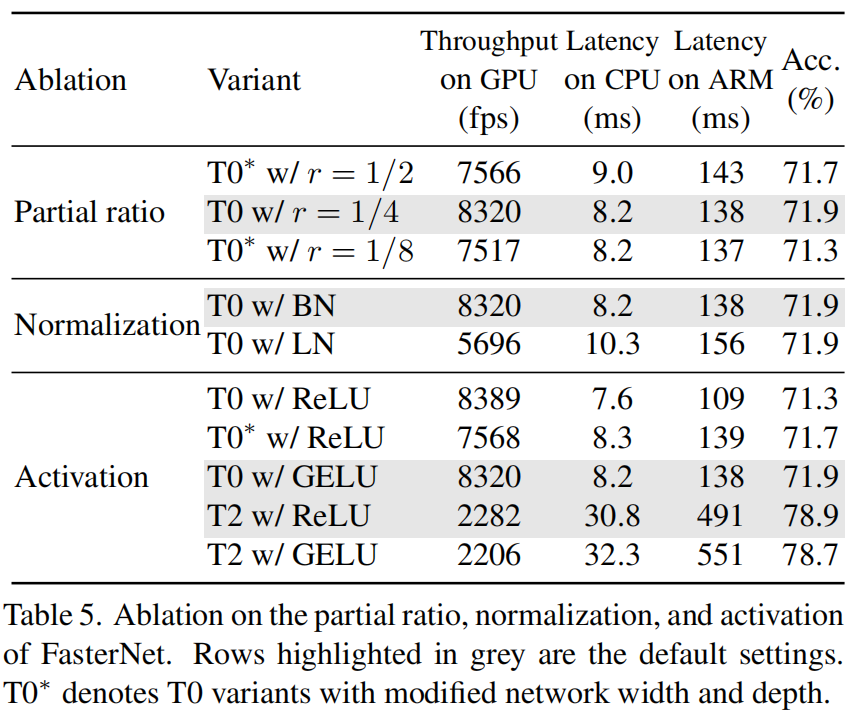
前言 为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。并且,如此低的FLOPS主要是由于运算符的频繁内存访问,尤其是深度卷积。因此,本文提出了一种新的partial convolution(PConv),通过同时减少冗余计算和内存访问可以更有效地提取空间特征。 基于PConv进一步提出FasterNet,在广泛的设备上实现了比其他网络高得多的运行速度,而不影响各种视觉任务的准确性。同时,实现了令人印象深刻的83.5%的TOP-1精度,与Swin-B不相上下,同时GPU上的推理吞吐量提高了49%,CPU上的计算时间也节省了42%。
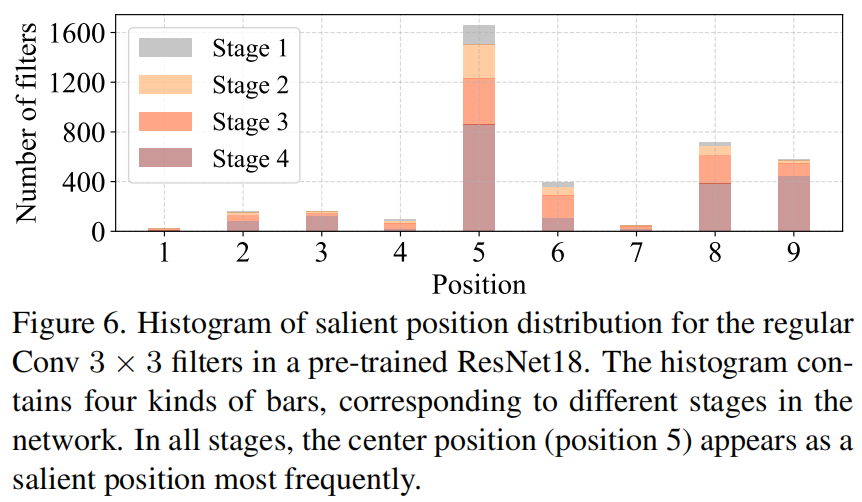
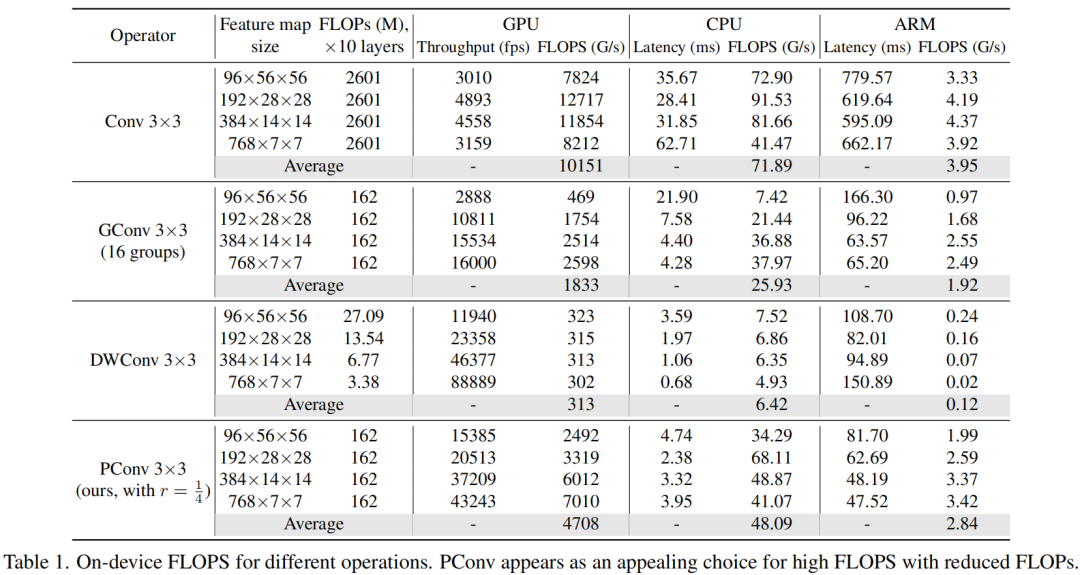
请注意,FLOPs与延迟之间的差异在之前的工作中也已被注意到,但由于它们采用了DWConv/GConv和具有低FLOPs的各种数据处理,因此部分问题仍未解决。人们认为没有更好的选择。
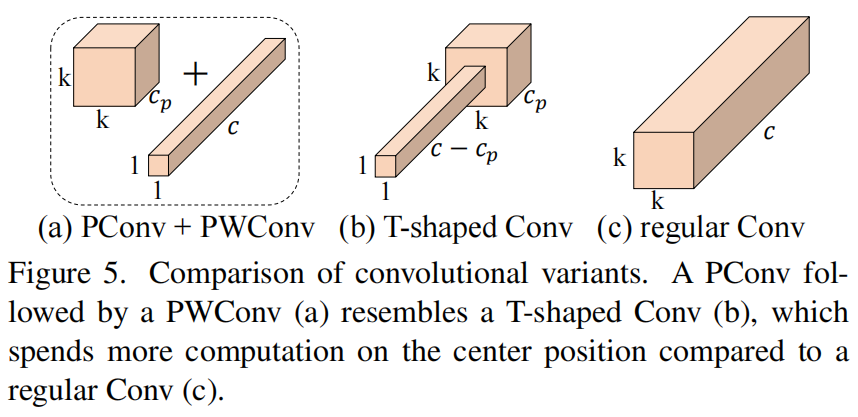
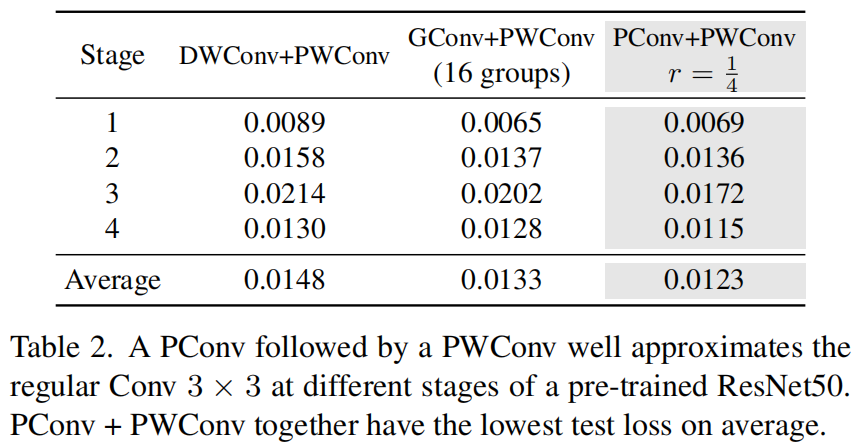
请注意,保持其余通道不变,而不是从特征图中删除它们。这是因为它们对后续PWConv层有用,PWConv允许特征信息流经所有通道。
使用道具 举报
1
4
10
18
8
12
28
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver手机版
Powered by Discuz! X3.4© 2001-2015 Comsenz Inc.



 发表于 2023-7-7 13:24:19
发表于 2023-7-7 13:24:19