|
|
论文类别有医学影像分割、医学影像增强、多模态表情包分类、微表情识别、遮挡人员重识别、动作识别等
【2023年3月1日】论文分享
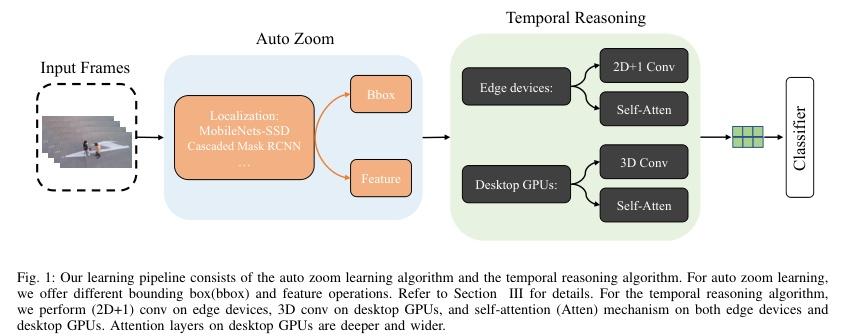
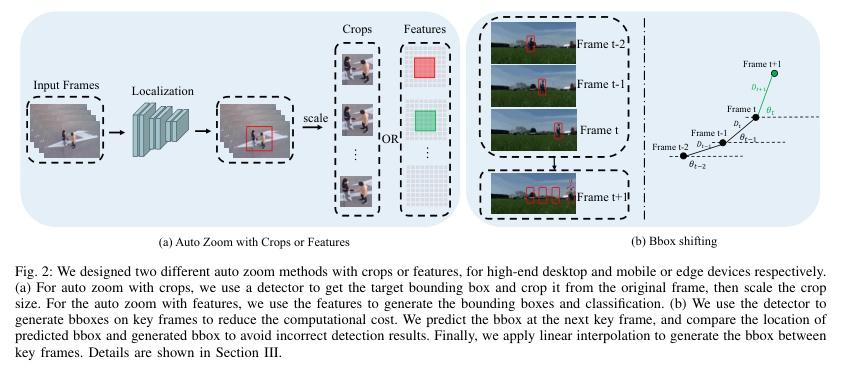
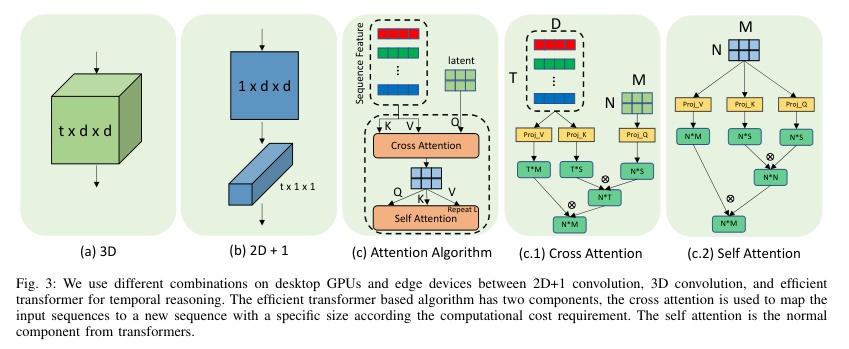
▌AZTR: Aerial Video Action Recognition with Auto Zoom and Temporal Reasoning

论文作者:Xijun Wang,Ruiqi Xian,Tianrui Guan,Celso M. de Melo,Stephen M. Nogar,Aniket Bera,Dinesh Manocha
论文链接:http://arxiv.org/abs/2303.01589v1
内容简介: 研究方向:动作识别。本研究提出一种针对无人机航拍视频的新方法,可以在边缘设备或移动设备上运行。该方法采用定制自动缩放来自动识别人类目标并适当缩放,从而更容易提取关键特征并降低计算负载。同时,还提出了一种高效的时间推理算法,以在可控的计算成本内捕捉时空领域内的动作信息。该方法在高端GPU桌面计算机和低功耗机器人和无人机的Robotics RB5平台上进行了实现和评估。实践中,在RoCoG-v2数据集上,Top-1准确度的改进为6.1-7.4%,在UAV-Human数据集上的改进为8.3-10.4%,在Drone Action数据集上的改进为3.2%。该研究的目标是提高无人机航拍视频动作识别的准确性和效率,使用的方法包括定制自动缩放和高效时间推理算法,最终取得了显著的改进效果。

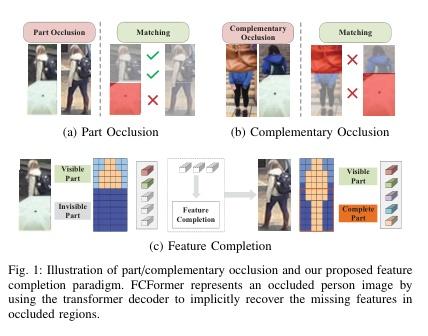
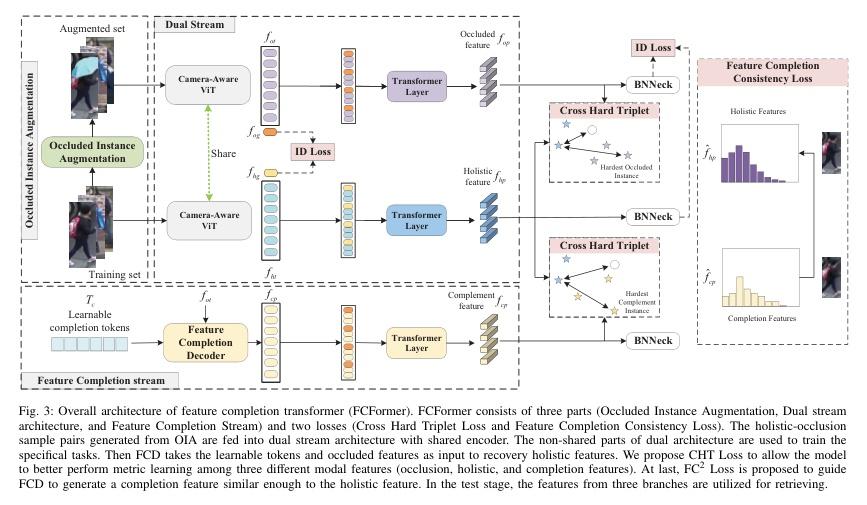
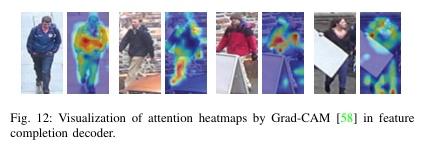
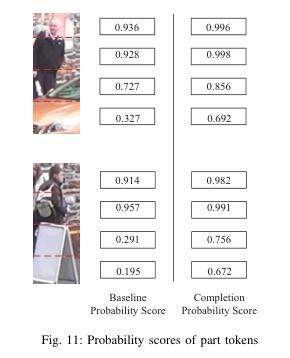
▌Feature Completion Transformer for Occluded Person Re-identification

论文作者:Tao Wang,Hong Liu,Wenhao Li,Miaoju Ban,Tuanyu Guo,Yidi Li
论文链接:http://arxiv.org/abs/2303.01656v1
内容简介: 本文提出一种新的方法——Feature Completion Transformer(FCFormer),用于解决遮挡人物重识别的问题。与现有的方法不同,该方法不会丢弃遮挡部分,而是通过隐式补充特征空间中的遮挡部分的语义信息。Occlusion Instance Augmentation(OIA)用于模拟真实和多样的遮挡情况,从而扩充训练集中的遮挡样本数量。之后,提出了一种双流架构,通过共享编码器从输入对中学习配对的鉴别特征。Feature Completion Decoder(FCD)旨在使用可学习令牌从自动生成的遮挡特征中汇总可能的信息,以补充遮挡区域的特征。最后,提出了交叉难三元组(CHT)损失来进一步缩小补全特征和提取特征之间的差距。FCFormer在五个具有挑战性的数据集上进行了大量实验,结果表明其在遮挡数据集上实现了卓越的性能,并且在遮挡重识别领域中取得了显著的优势。

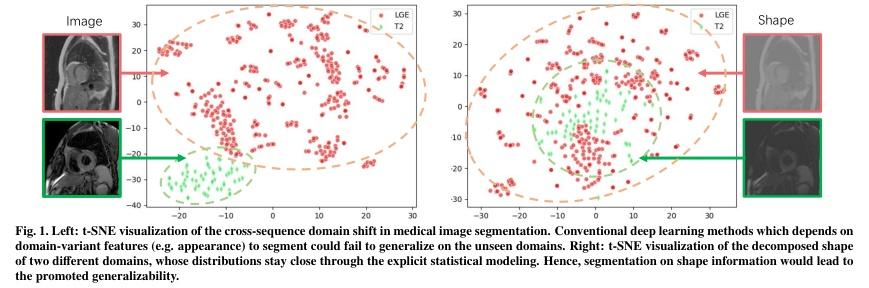
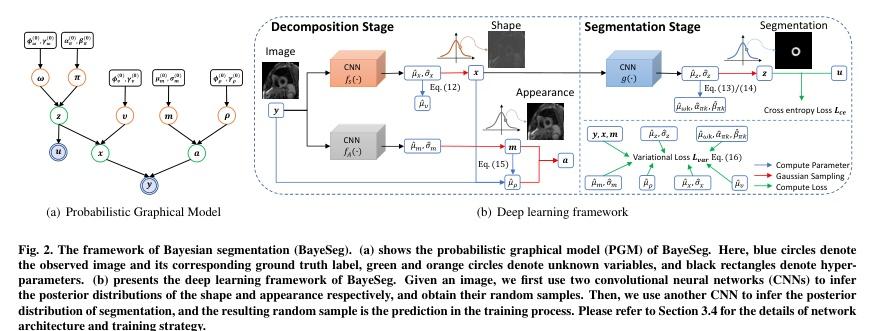
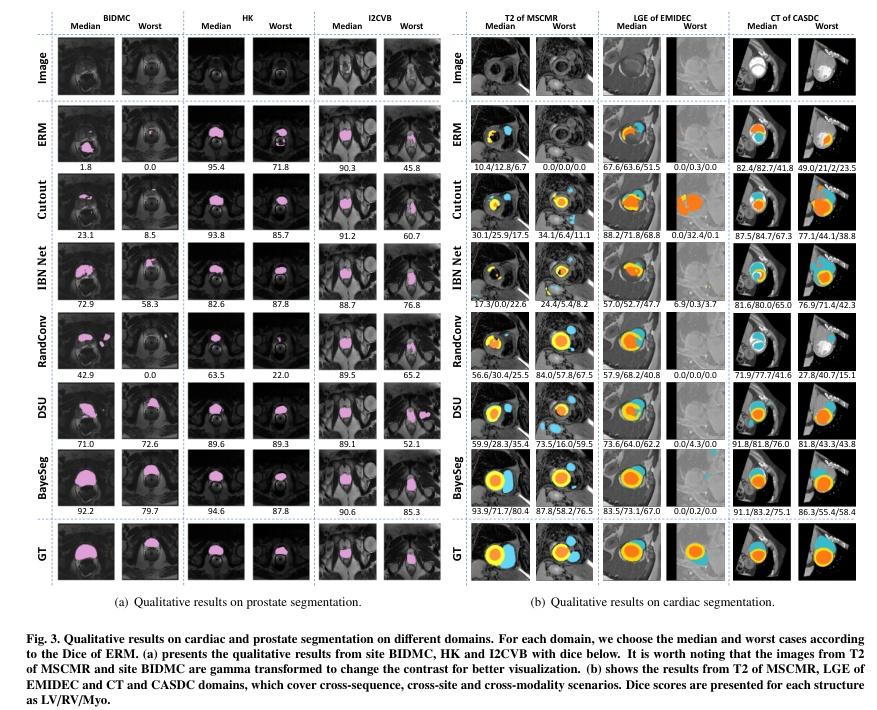
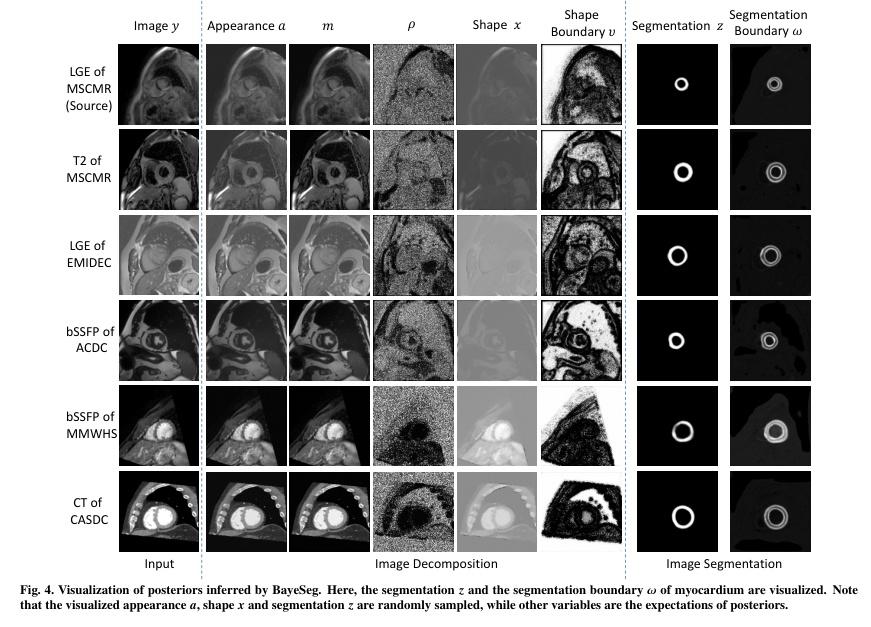
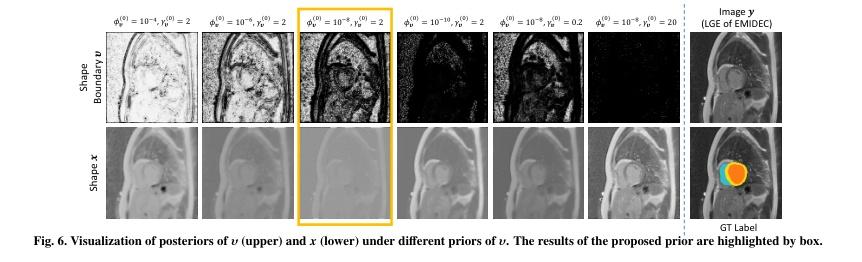
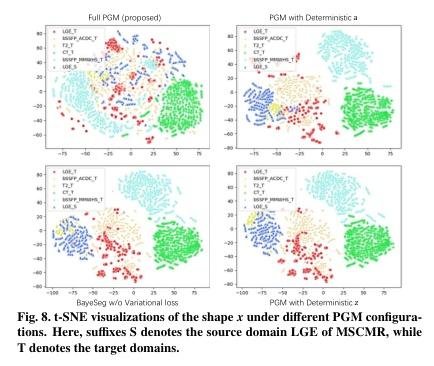
▌BayeSeg: Bayesian Modeling for Medical Image Segmentation with Interpretable Generalizability

论文作者:Shangqi Gao,Hangqi Zhou,Yibo Gao,Xiahai Zhuang
论文链接:http://arxiv.org/abs/2303.01710v1
项目链接: https://zmiclab.github.io/projects.html
内容简介: 研究方向:医学图像分割。本文研究如何通过贝叶斯建模来增强深度学习分割方法的泛化能力,同时提高可解释性。该方法在医学图像分割任务中具有显著的实验效果,能够解决不同医学图像系统之间的领域偏移问题。具体方法是将图像分解为空间相关变量和空间变异变量,并分别为它们分配层次贝叶斯先验,以明确表示稳定形状和特定外观信息。然后,将分割建模为仅与形状相关的局部平滑变量。最后,采用变分贝叶斯框架推断这些可解释变量的后验分布,实现深度贝叶斯分割。实验结果表明,该方法在前列腺分割和心脏分割任务中均具有良好的效果,并且还具有一定的可解释性。


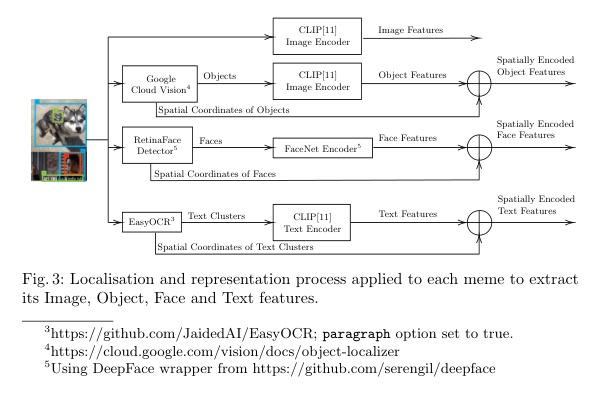
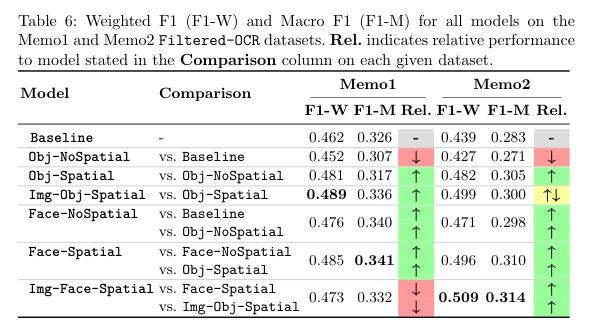
▌Meme Sentiment Analysis Enhanced with Multimodal Spatial Encoding and Facial Embedding

论文作者:Muzhaffar Hazman,Susan McKeever,Josephine Griffith
论文链接:http://arxiv.org/abs/2303.01781v1
内容简介: 研究方向:多模态表情包分类(Multimodal Meme Classification)。本文研究如何在表情包的图像和文本两个模态中考虑它们的相对位置对分类的影响。通过将视觉对象、人脸和文本聚类的相对位置信息作为输入,以及将面部嵌入作为图像特征的增强,提出了一种有效的多模态表情包分类方法。实验结果表明,相对位置信息的加入可以显著提高表情包分类的准确性,并且在不需要人类文本验证的情况下,该方法也能超过基线模型。

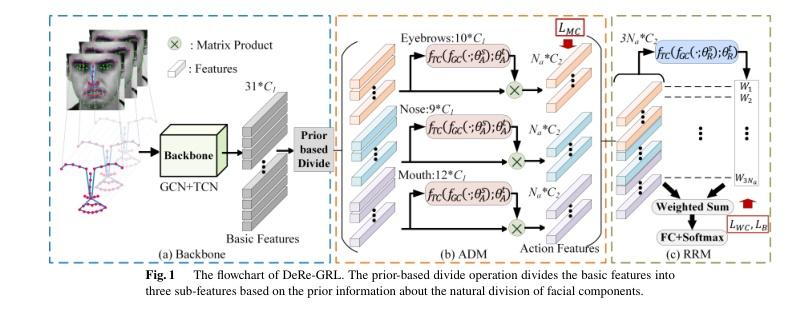
▌Prior Information based Decomposition and Reconstruction Learning for Micro-Expression Recognition

论文作者:Jinsheng Wei,Haoyu Chen,Guanming Lu,Jingjie Yan,Yue Xie,Guoying Zhao
论文链接:http://arxiv.org/abs/2303.01776v1
内容简介: 研究方向:微表情识别(MER)。本文提出一种新的模型DeRe-GRL,该模型能够在符合先验信息的情况下,以可解释的方式学习微表情运动特征。DeRe-GRL包括两个模块:Action Decomposition Module (ADM)和Relation Reconstruction Module(RRM)。ADM将面部关键组件的几何运动特征划分为多个子特征,并学习映射矩阵将这些子特征映射到多个行为特征。RRM学习权重以加权所有行为特征以建立行为特征之间的关系。实验结果表明了所提出模块的有效性,该方法取得了竞争性能。
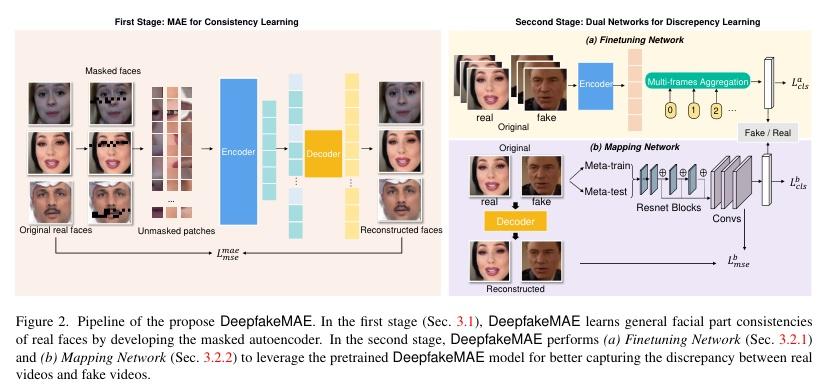
▌DeepfakeMAE: Facial Part Consistency Aware Masked Autoencoder for Deepfake Video Detection

论文作者:Juan Hu,Xin Liao,Difei Gao,Satoshi Tsutsui,Zheng Qin,Mike Zheng Shou
论文链接:http://arxiv.org/abs/2303.01740v1
内容简介: 研究方向:Deepfake检测(detection)。本文提出了一种新的Deepfake检测模型DeepfakeMAE,该模型能够利用所有面部部位之间的一致性来检测Deepfake。首先,通过预训练掩码自编码器来学习面部部位的一致性,然后利用预训练的编码器和解码器分别构建双网络,以最大化真实视频和Deepfake视频之间的差异。实验结果表明,DeepfakeMAE是非常有效的,特别是在跨数据集检测方面,平均优于先前的最先进方法3.1% AUC。

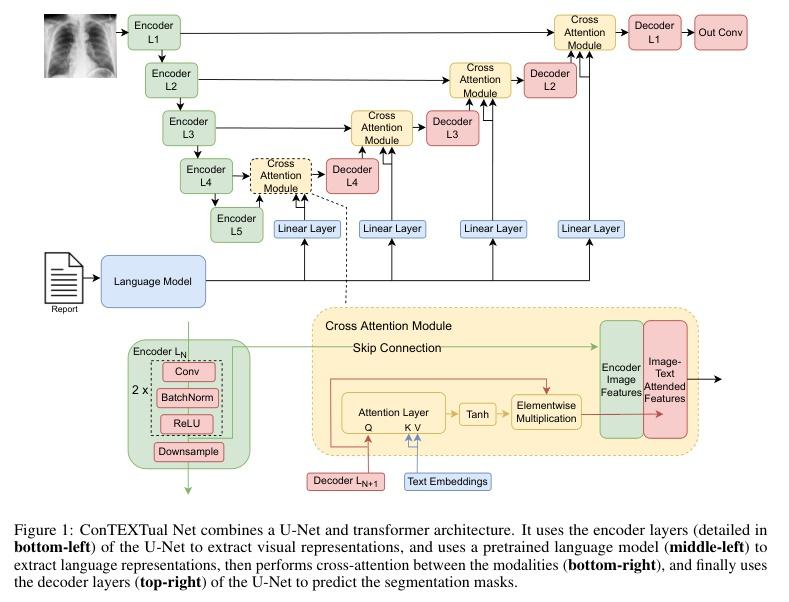
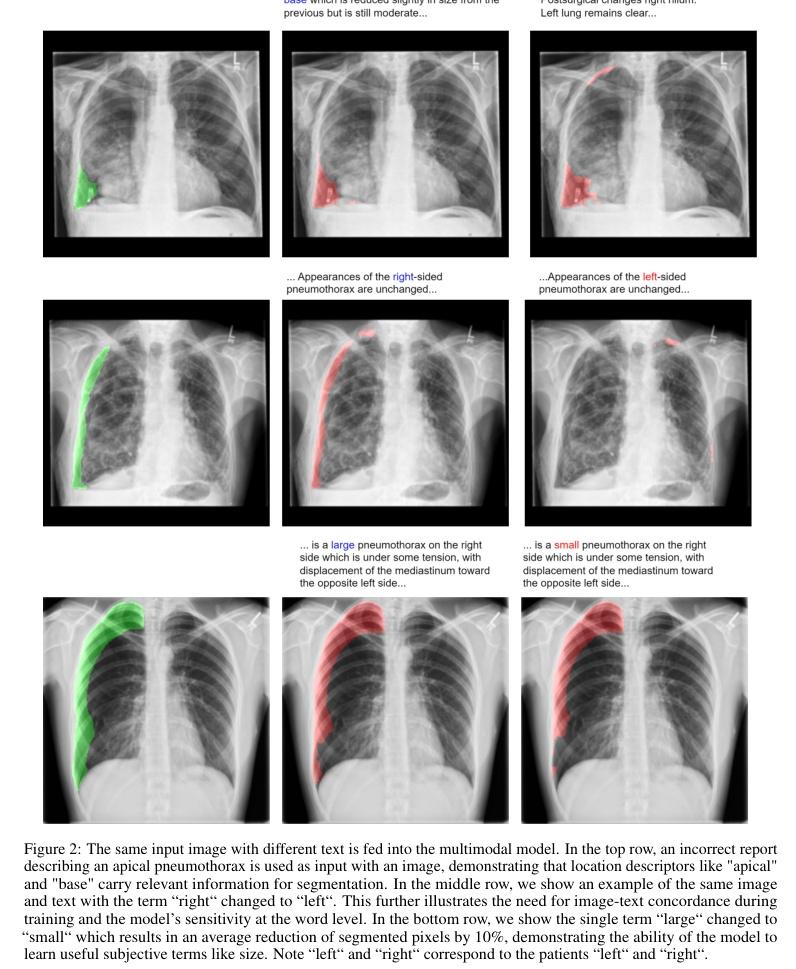
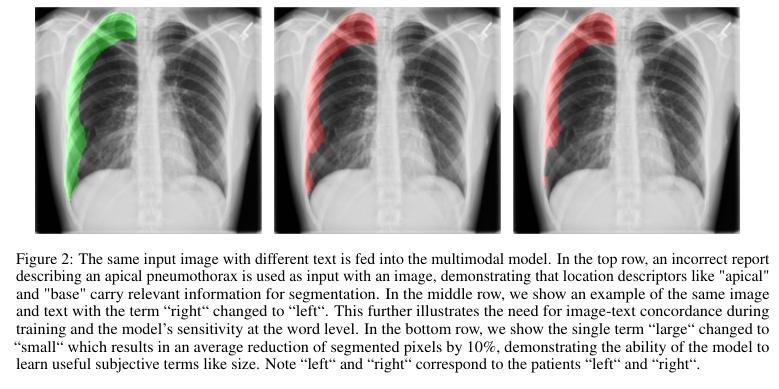
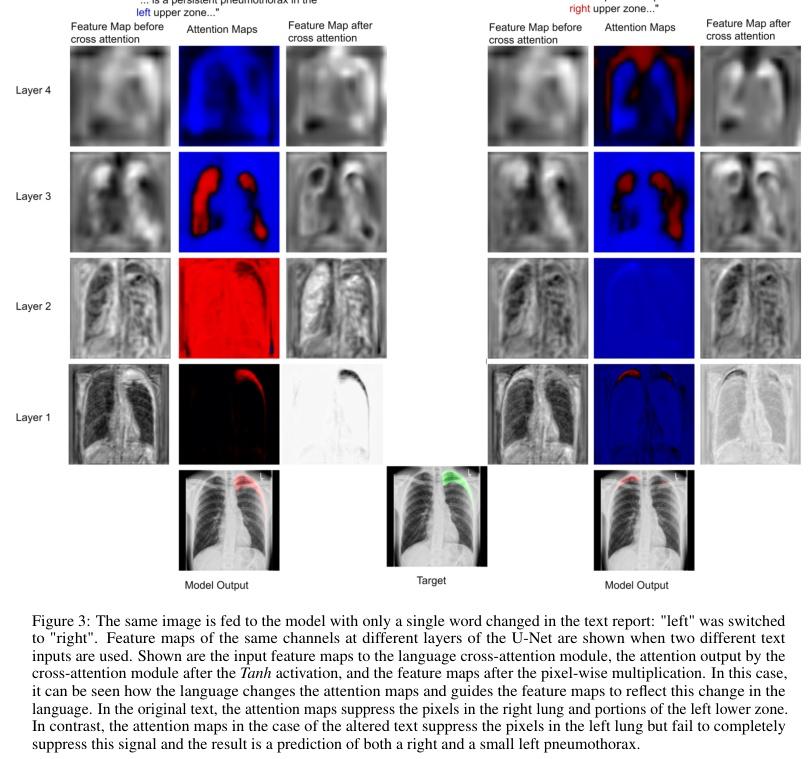
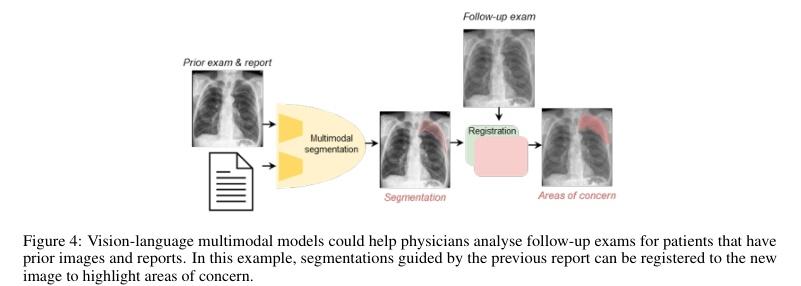
▌ConTEXTual Net: A Multimodal Vision-Language Model for Segmentation of Pneumothorax

论文作者:Zachary Huemann,Junjie Hu,Tyler Bradshaw
论文链接:http://arxiv.org/abs/2303.01615v1
内容简介: 本文探讨了将医学影像中的自由文本报告用于指导肺气胸分割的视觉语言模型。该模型命名为ConTEXTual Net,可以检测和分割胸部X线片中的肺气胸。该模型结合了自由文本报告中的描述性语言以提高分割性能,实现了0.72±0.02的Dice分数,这与主要医生标注者和其他医生标注者之间的一致性水平(0.71±0.04)相似,并优于U-Net。通过实验验证了文本信息对于提高性能的关键作用,并提出了一些数据增强方法以维持图像-文本一致性。
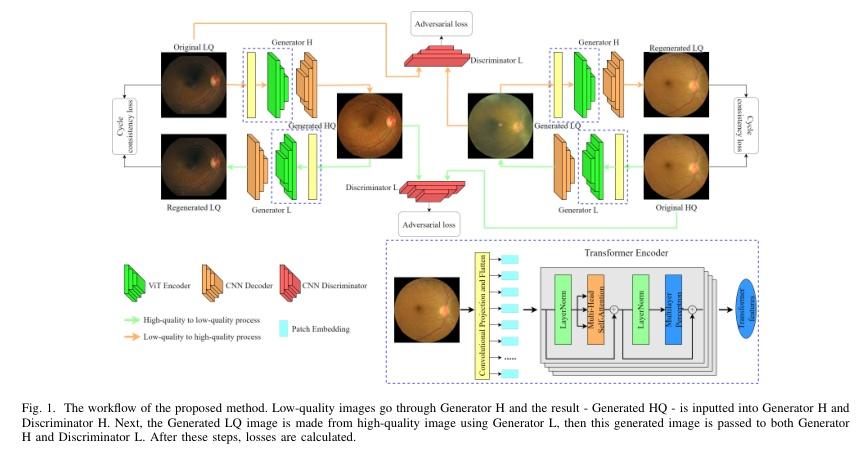
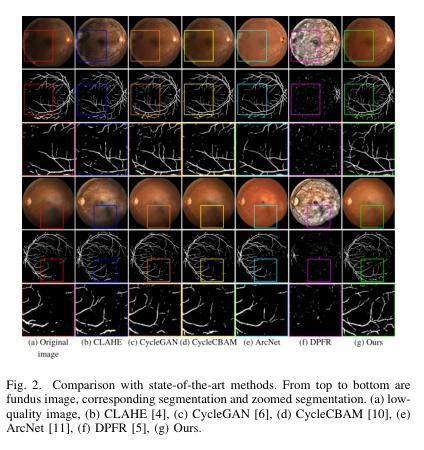
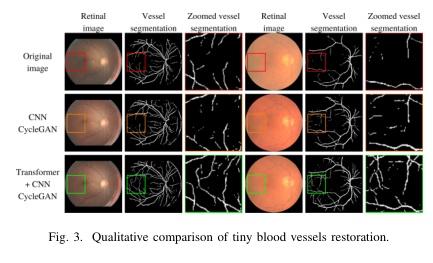
▌Retinal Image Restoration using Transformer and Cycle-Consistent Generative Adversarial Network

论文作者:Alnur Alimanov,Md Baharul Islam
论文链接:http://arxiv.org/abs/2303.01939v1
内容简介: 研究方向:医学图像增强。本文提出一种基于vision transformer和卷积神经网络的视网膜图像增强方法,旨在提高医学图像的质量,消除模糊、噪声、光照干扰和色彩失真等问题。该方法通过对抗生成网络来实现图像翻译,包括两个生成器和两个鉴别器。其中,生成器由vision transformer(ViT)编码器和卷积神经网络(CNN)解码器组成,而鉴别器则包括传统的CNN编码器。实验结果表明,该方法在定量和定性测试中都取得了显著的提升,PSNR分别为31.138 dB和27.798 dB,SSIM分别为0.919和0.904。
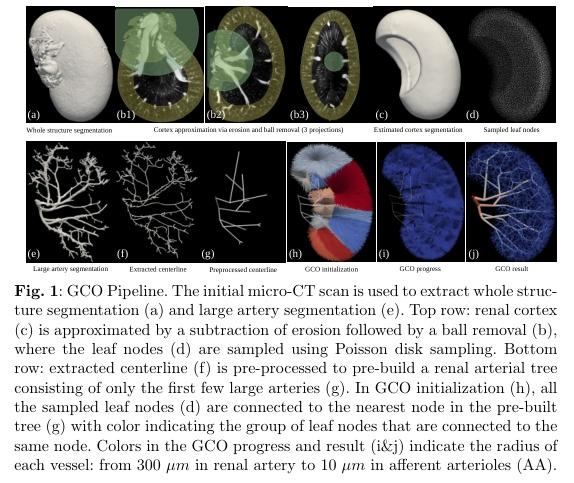
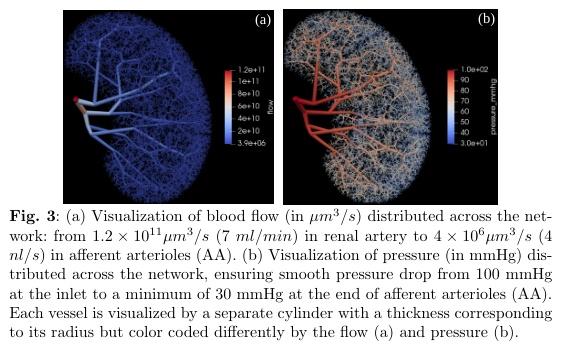
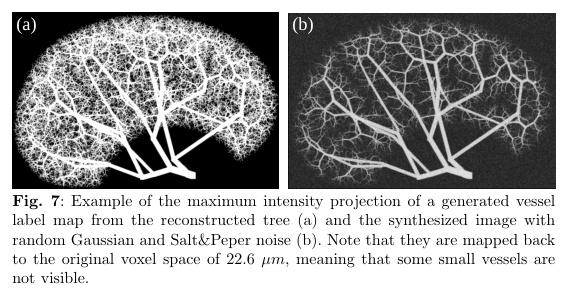
▌A Hybrid Approach to Full-Scale Reconstruction of Renal Arterial Network

论文作者:Peidi Xu,Niels-Henrik Holstein-Rathlou,Stinne Byrholdt Søgaard,Carsten Gundlach,Charlotte Mehlin Sørensen,Kenny Erleben,Olga Sosnovtseva,Sune Darkner
论文链接:http://arxiv.org/abs/2303.01837v1
内容简介: 肾脏血管是一个重要的分配资源网络,但由于空间和时间分辨率有限,目前没有成像技术可以评估肾脏血管结构和功能。为了开发真实的肾功能计算机模拟,并基于人工智能开发新的基于影像的诊断方法,需要有一个真实的肾脏血管完整模型。该研究采用半自动分割大动脉和通过微CT扫描估计皮层面积作为起点,并采用全局构造优化算法来生成更小的血管,以建立个体化的肾血管网络模型。结果显示,重建数据与大鼠肾脏已有的解剖数据在形态和血流动力学参数方面具有统计学对应关系。
 |
|



 发表于 2023-7-2 20:10:48
发表于 2023-7-2 20:10:48