|
|
本文为“Dive into Big Model Training”[9]笔记。 随着chatGPT的火爆出圈,大模型也逐渐受到越来越多研究者的关注。因此,本篇文章主要解读大模型训练过程中涉及到的技术,帮助大家寻找一个研究落点。在进入大模型的学习之前,我们需要知道什么是大模型、为什么需要大模型?
什么是大模型?
顾名思义,大模型指网络规模巨大的深度学习模型,具体表现为模型的参数量规模较大,其规模通常在千亿级别。
为什么需要大模型?
有一份来自OpenAI的研究报告指出[1],模型的性能(指精度)通常与模型的参数规模息息相关。模型参数规模越大,模型的学习能力越强,最终的精度也将更高。
大模型训练面临哪些挑战?
模型参数规模的不断增大为模型训练带来计算、存储、通信等方面的挑战。
1、计算:如今GPU或其他加速器的发展速度已经远远无法跟上模型参数和数据量的增长速度。因此,在面对规模如此之大的模型时,底层系统的计算压力也在不断增长。下图是在单块NVIDIA V100 GPU上训练语言模型的耗时。可以看到,训练时间是算法工程师所无法接受的长度。
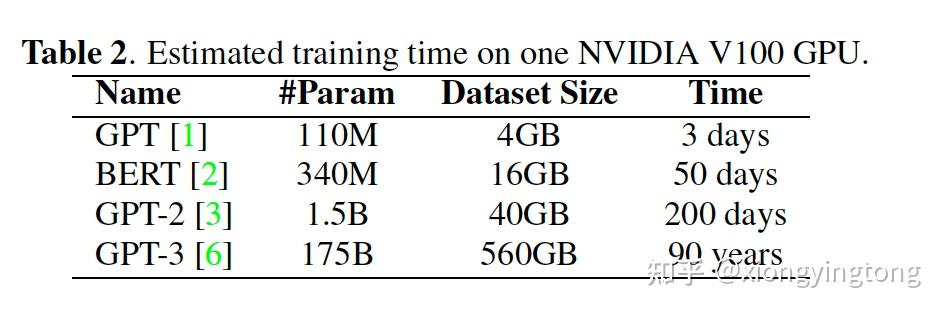
图1
2、存储:随着模型规模的不断增大,现有的加速器如GPU已经无法完全容纳整个模型。例如,目前GPU的最大显存容量为80GB,这远远不够进行模型训练。
3、网络通信:为了解决计算和存储问题,现在最普遍的模型训练方法是分布式训练。通常而言,任何东西放到分布式环境下,其解决方法将会比单机环境下要复杂的多。在分布式训练中,最需要重视的问题是如何尽可能减少节点之间的通信。节点之间的通信问题在大模型训练中也是格外需要注意的。
如何应对这些挑战?以下这三个技术将解决以上挑战:
- Distributed Training
- Memory Saving
- Model Sparsity
Distributed Training
个人认为,分布式训练分为数据并行和模型并行。其中模型并行又分为pipeline并行和张量并行。
数据并行
作为最简单和最常见的并行方式,数据并行主要针对的是单卡无法完全存储全部数据集的情况。在数据并行中,数据被划分并分别分配给各个计算device,每个device都保有一份模型副本和不同的数据。如此,每个device便可以同时进行训练。在进行下一次训练迭代前,每个device需要对模型参数进行同步来保证模型参数的一致性。常见的同步方式有以下三种:
- Bulk Synchronous Parallel(BSP):每个device在完成一次迭代训练后就进行参数同步。优点是能够始终保证每个device上的模型参数一致,缺点是同步时间可能会过长,导致某些device出现空闲等待的情况。
- Asynchronous Parallel(ASP):每个device在完成一次迭代训练后不进行参数同步,直接进行下一次迭代训练。这种同步方式减少了每个device的空闲等待时间,然而使得每个device上的模型参数不一致,从而导致精度会受到影响。
- Stale Synchronous Parallel(SSP):通过保存不同版本的模型参数,每个device需要更新参数时,将会使用前几次迭代过程中产生的梯度来更新参数。这种方式结合了同步和异步的方式,来达到device空闲等待时间和模型训练精度之间的平衡。
进一步学习可以参考Pytorch中的DP和DDP[2]。
Pipeline并行
Pipeline并行是数据并行和模型并行的结合体。在pipeline并行中的模型并行主要指的是在layer的角度来对模型进行切分。主要思想是将一个minibatch切分为多个microbatches,使得每个device能够同时处理多个microbatches。同样的,pipeline并行也有同步和异步并行。
GPipe[3]是同步并行的一个典型代表。其中心思想是,在一次minibatch训练中,等所有的microbatches前向传播结束后,再进行后向传播。
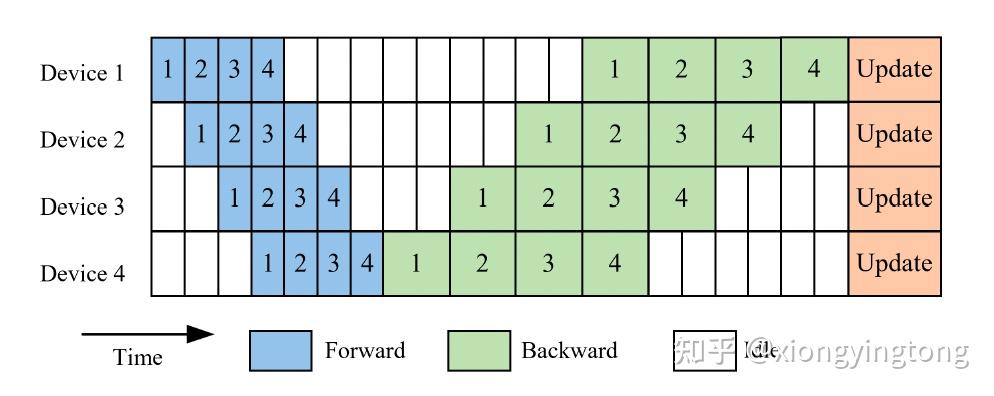
图2
图2描述了GPipe的主要思想。模型被划分成4份,分别散步在4个device上。一个minibatch被划分成4个microbatches。在最后一个microbatches完成后向传播后,各个device对模型参数进行更新。尽管如此,从图2中可以看出,各个device的空闲时间依旧较长。
Pipedream[4]是异步并行的典型工作。
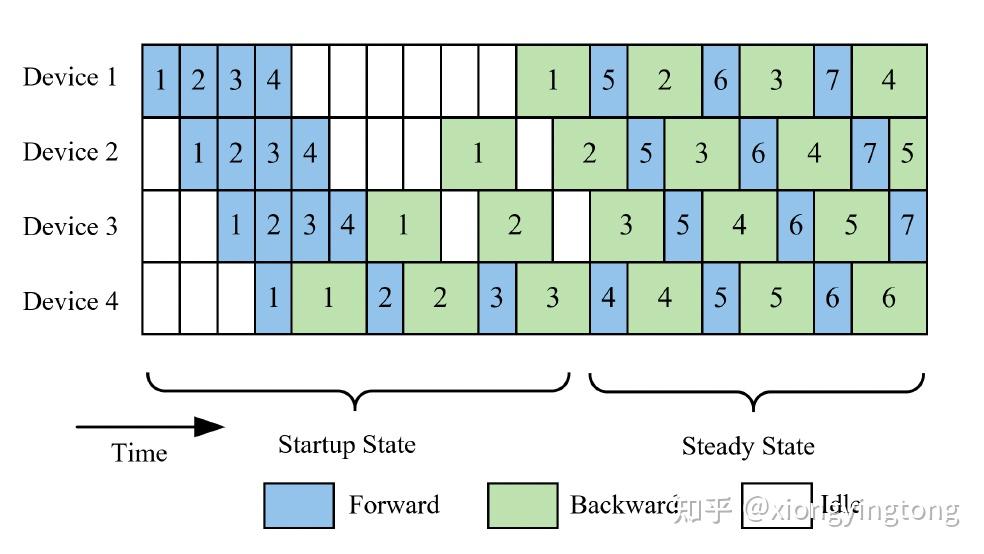
图3
与GPipe不同,当每个microbatch完成前向传播之后,立即开始后向传播。这种训练调度方式相比于GPipe而言,在存储和计算方面均更高效。
为了进一步减少Pipedream中的device空闲时间,interleaved 1F1B[5]调度方式被提出。与Pipedream不同,当一个minibatch中的microbatches未完全被处理时,就开始处理下一个minibatch以提高device的利用率。
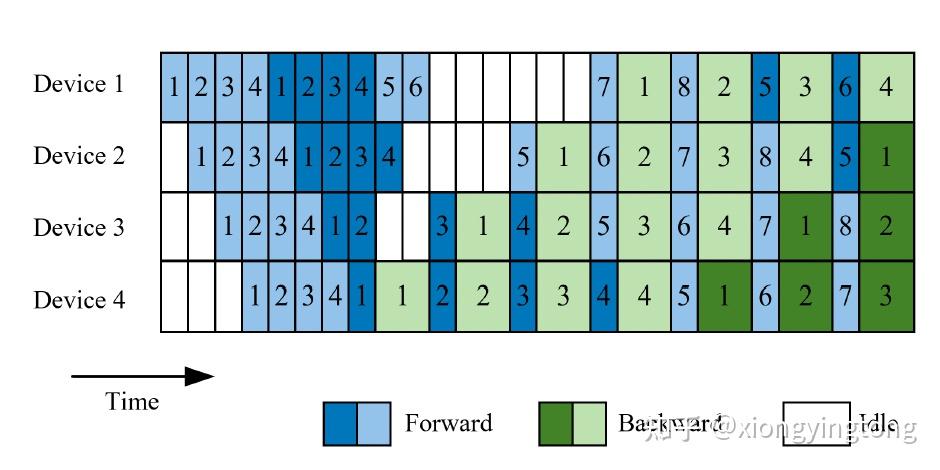
图4
张量并行
张量并行是从张量的角度来对张量沿着某个维度进行切分,因此叫做张量并行(可以和数据并行和pipeline并行同时使用)。个人认为,张量并行的本质是矩阵切分。
根据切分的维度不同,张量并行有1D、2D、2.5D并行方式。
由于深度学习训练的本质是矩阵计算,因此下面将以矩阵计算为例。Megatro-LM[6]是NVIDIA针对transformer提出的1D张量并行。公式1展示了一个常见的计算模块,包括一个矩阵计算和一个非线性激活层。其中GeLu表示非线性激活函数。
Y=GeLu(XA)
对于矩阵X和A有两种划分方式。
方式一:
A=\left[ A1, A2\right]^T , X=\left[ X1, X2 \right]
XA=X1A1+X2A2
每个device分别负责一部分矩阵计算,由于 GeLu(XA)\ne GeLu(X1A1+X2A2) ,因此在计算最终结果之前,device之间需要进行同步来获取最终的XA结果。
方式二:
将A在列的维度进行划分, A=\left[ A1,A2 \right] ,因此 XA=\left[ XA1, XA2 \right]
Y=\left[ Y1, Y2 \right]=\left[ GeLu(XA1), GeLu(XA2) \right]
通过在列维度进行划分避免了方式一中出现的需要同步的问题。
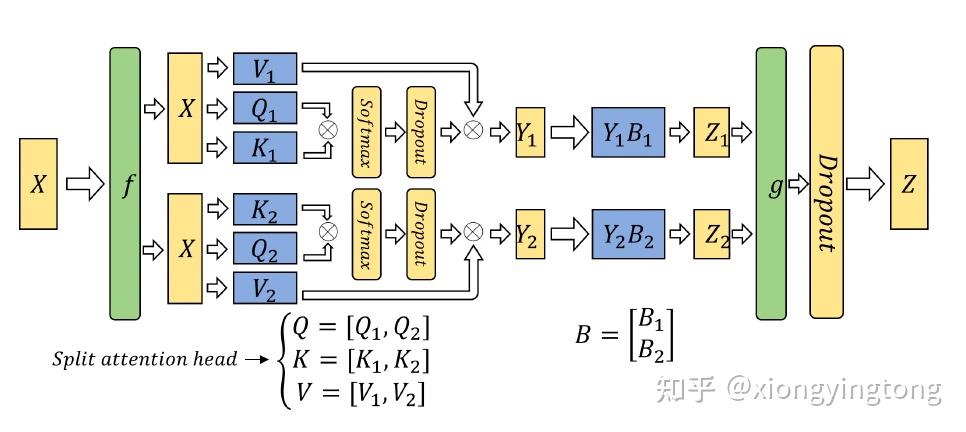
图5
图5展示了transformer的张量并行流程图。
然而,Megatron-LM算法容易受到存储限制的问题。下面展示一个2D张量并行的例子来解决1D并行中的存储受限问题。

图6
Memory Saving
除了在计算方面有相应的解决方法外,也有不少研究工作从减少存储消耗方面来提高大模型训练的存储效率。常见的技术有:
- Activation Checkpointing
- Mix Precision Training
- Zero Redundancy Optimizer
Activation Checkpointing
又名activation recomputation、gradient checkpointing或者re-materialization
checkpointing技术比较好理解,在前向传播过程中,有选择性的丢弃一些产生的中间激活值,当反向传播需要使用这些激活值时,再依据上一个保存的激活值来计算出这些需要的激活值来帮助完成反向传播。这样一来,便可以大大减少训练过程中所需要的存储空间。然而,checkpointing技术在有些模型例如ResNet50和U-Net上效果不佳。
Mix Precision Training
通常而言,在训练过程中,模型参数通常以32位浮点数保存。混合精度训练的主要思想是在前向和反向计算中,用16位浮点数代替这些32位浮点数来减少训练过程中的存储消耗。
混合精度训练通常有三种方式:
- FP32 master copy of weights:保存一份32位浮点数的参数副本,当需要更新模型参数时,使用这份副本,其余计算过程使用16位浮点数参数。
- Loss scaling:为了避免16位浮点数出现下溢的情况,可以在前向传播过程中对loss进行缩放,最后在进行参数更新前将梯度反向缩放。
- Arithmetic precision: 对于有些模型而言,在训练过程中需要使用到32位浮点数进行部分计算,然后再转换为16位浮点数进行存储。可以借助NVIDIA的Tensor Core来实现。
Zero Redundancy Optimizer(ZeRO)
ZeRO[7]是deepspeed团体的成果,提供了两个技术来优化存储。
ZeRO-DP主要用于优化模型状态所占用的存储;ZeRO-R主要用于优化除了模型参数、状态和梯度,剩下的存储空间。关于ZeRO的详细技术,在未来会专门写一篇文章。
Model Sparsity
到目前为止,上述所提出的所有技术都是从系统的角度来提高大模型训练效率。在这一节将要介绍从模型本身出发的优化技术。Mixture-of-Expert(MOE)[8]是model sparsity design中的一种。
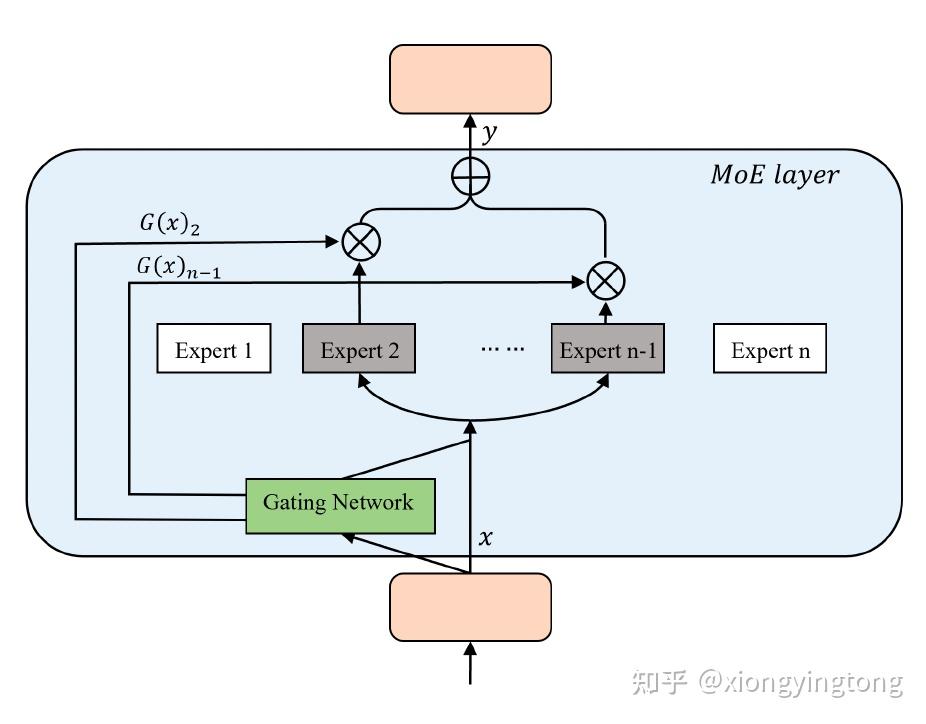
图7
图7展示了MOE的单层结构,其中包括一个gating network和若干个expert。gating network负责决定给每个expert的权重。MOE可以形式化为公式2:
y=\sum{(G(x)_iE_i(x))}
其中, G(x)_i 表示gating network分配给第i个expert的权重, E_i(x) 表示第i个expert的输出。因此,可知gating network在MOE中起着关键作用。
下面介绍两种gating network
Softmax Gating
G(x)=Softmax(x\cdot W_g)
Noisy Top-K Gating:在softmax gating的基础上,引入高斯噪音并选择top k值
G(x)=Softmax(KeppTopK(H(x), k))
H(x)_i=(x\cdot W_g)_i+\epsilon\cdot Softplus((x\cdot W_{noise})_i)
到此为止,关于大模型训练的技术总结就如上啦,欢迎各位大佬补充并指正文中的不当之处。
文章所有图片均来源[9] 参考文献:
[1] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprint arXiv:2001.08361, 2020.
[2] S. Li, Y. Zhao, R. Varma, O. Salpekar, P. Noordhuis, T. Li, A. Paszke, J. Smith, B. Vaughan, P. Damania et al., “Pytorch distributed: Experiences on accelerating data parallel training,” arXiv preprint arXiv:2006.15704, 2020.
[3] Y. Huang, Y. Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu et al., “Gpipe: Efficient training of giant neural networks using pipeline parallelism,” Advances in neural information processing systems, vol. 32, 2019.
[4] A. Harlap, D. Narayanan, A. Phanishayee, V. Seshadri, N. Devanur, G. Ganger, and P. Gibbons, “Pipedream: Fast and efficient pipeline parallel dnn training,” arXiv preprint arXiv:1806.03377, 2018.
[5] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro et al., “Efficient large-scale language model training on gpu clusters using megatron-lm,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–15.
[6] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv:1909.08053, 2019.
[7] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He, “Zero: Memory optimizations toward training trillion parameter models,” in SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–16.
[8] N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” arXiv preprint arXiv:1701.06538, 2017.
[9] Wu F, Wang Q, Bian J, et al. A Survey on Video Action Recognition in Sports: Datasets, Methods and Applications[J]. IEEE Transactions on Multimedia, 2022. |
|



 发表于 2023-4-26 18:53:00
发表于 2023-4-26 18:53:00