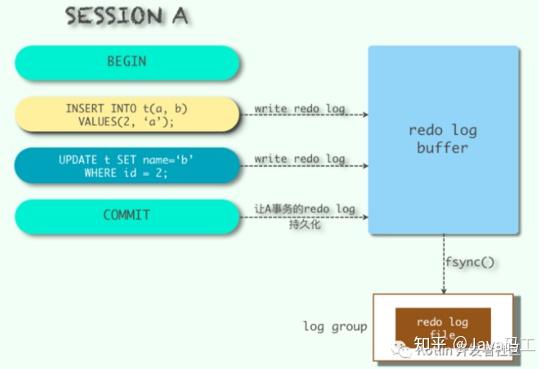
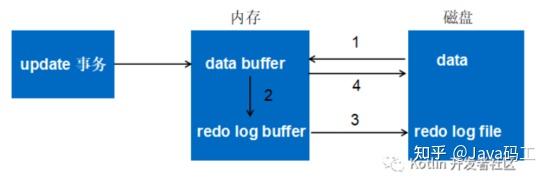
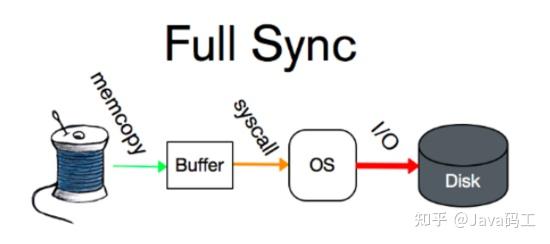
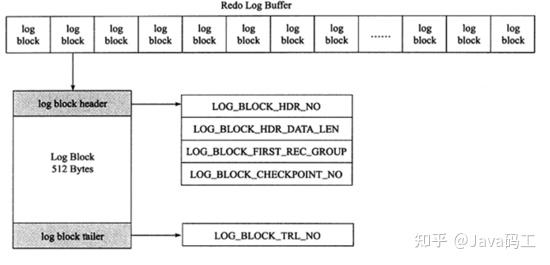
Force Log at Commit机制实现了事务的持久性。 在内存中操作时,日志被写入重做日志缓冲区。但在事务提交之前,必须首先将所有日志写入磁盘上的重做日志文件。
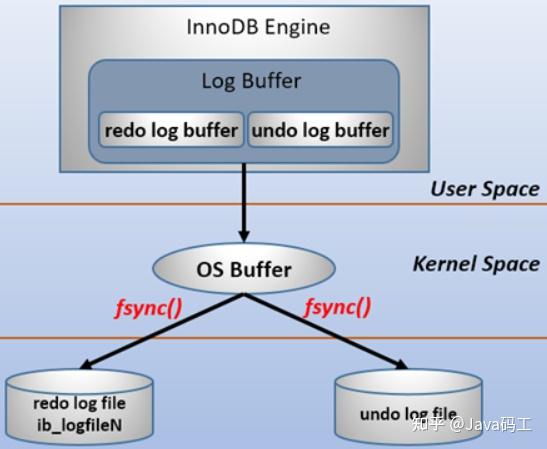
为了确保每个日志都写入重做日志文件,必须使用一个fsync系统调用,确保OS buffer中的日志被完整地写入磁盘上的log file。
fsync系统调用:需要你在入参的位置上传递给他一个fd,然后系统调用就会对这个fd指向的文件起作用。fsync会确保一直到写磁盘操作结束才会返回,所以当你的程序使用这个函数并且它成功返回时,就说明数据肯定已经安全的落盘了。所以fsync适合数据库这种程序。
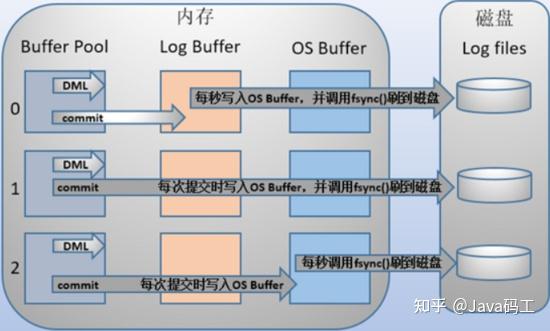
当innodb_flush_log_at_trx_commit值为0时。 事务提交时不将log buffer写入到os buffer,而是每秒写入os buffer并调用fsync()写入到log file on disk中。这实际上相当于在内存中维护了一个用户设计的缓冲区,它减少了和os buffer之间的数据传输,有更好的性能。每秒写入磁盘,系统崩溃会丢失1s的数据。
当innodb_flush_log_at_trx_commit值为2时。 每次提交都仅写入os buffer,然后每秒调用fsync()将os buffer中的日志写入到log file on disk中。虽然说我们是每秒调用fsync()将os buffer中的日志写入到log file on disk中,但是平时即使不调用fsync,数据也会2自主地逐渐进入磁盘。所以当发生系统崩溃,相比第二种情况,会丢失较少的数据。但同时,由于每次提交都写入os buffer,所以相比第二种情况,性能会差一些,但还是比第一种好的。
无论是哪种情况
1.6.3 一个小的性能测试
几个选项之间的性能差距是极大的,下面做一个简单的测试。
#创建测试表
drop table if exists test_flush_log;
create table test_flush_log(id int,name char(50))engine=innodb;
#创建插入指定行数的记录到测试表中的存储过程
drop procedure if exists proc;
delimiter $$
create procedure proc(i int)
begin
declare s int default 1;
declare c char(50) default repeat('a',50);
while s<=i do
start transaction;
insert into test_flush_log values(null,c);
commit;
set s=s+1;
end while;
end$$
delimiter ;下面均插入十万条记录。
Ⅰ 当innodb_flush_log_at_trx_commit值为1时
test> call proc(100000)
[2021-07-25 13:22:02] completed in 27 s 350 ms需要长达27.35s。
Ⅱ 当innodb_flush_log_at_trx_commit值为2时
test> set @@global.innodb_flush_log_at_trx_commit=2;
test> truncate test_flush_log;
test> call proc(100000)
[2021-07-25 13:27:33] completed in 5 s 774 ms只需5.774s,性能大大提升。
Ⅲ 当innodb_flush_log_at_trx_commit值为0时
test> set @@global.innodb_flush_log_at_trx_commit=0;
test> truncate test_flush_log;
test> call proc(100000)
[2021-07-25 13:30:34] completed in 3 s 537 ms只需3.537s,性能更高。
显然,innodb_flush_log_at_trx_commit值为1时性能差得非常明显,改为0和2后性能都有大幅提升,其中0更快但相比2提升不大。
虽然改为0和2可以大幅提升性能,但会严重影响安全性。 我们可以通过修改存储过程,将事务的创建和提交放到循环外,统一提交,减少了IO频率。
drop procedure if exists proc;
delimiter $$
create procedure proc(i int)
begin
declare s int default 1;
declare c char(50) default repeat(&#39;a&#39;,50);
start transaction;
while s<=i DO
insert into test_flush_log values(null,c);
set s=s+1;
end while;
commit;
end$$
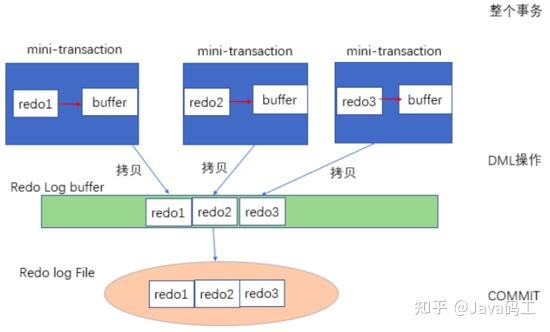
delimiter ;1.6.4 迷你事务mini-transaction
在聚集索引列的操作中,MySQL是这样设计的。对一条delete语句
delete from t where a = 1假如a有聚集索引(主键),那么不会进行真正的删除,而是在主键列等于1的记录处设置delete flag为1,即把记录保存在B+树中。同理,对于update操作,不是直接更新记录,而是把旧记录标识给删除,再创建一条新记录。
那么,旧版本记录什么时候真正的删除呢?
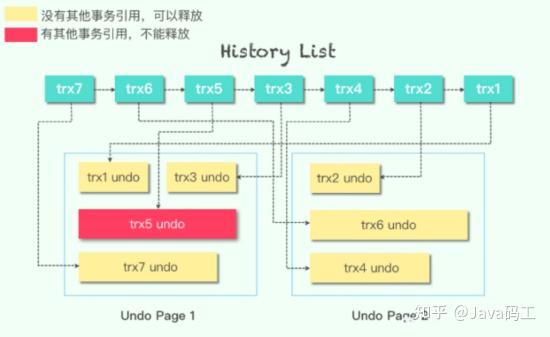
InnoDB使用undo日志进行旧版本的删除操作,这个操作称为purge操作。InnoDB开辟了purge线程进行purge操作,并且可以控制purge线程的数量,每个purge线程每10s 进行一次purge操作。
InnoDB的undo log设计
dirty page too much checkpoint。脏页太多时强制触发检查点,目的是为了保证缓存有足够的空闲空间。too much的比例有变量 innodb_max_dirty_pages_pct 控制,MySQL 5.6默认的值为75,即当脏页占缓冲池的百分之75后,就强制刷一部分脏页到磁盘。
(1).首先修改内存中的数据页,并在数据页中记录LSN,暂且称之为data_in_buffer_lsn;
(2).并且在修改数据页的同时(几乎是同时)向redo log in buffer中写入redo log,并记录下对应的LSN,暂且称之为redo_log_in_buffer_lsn;
(3).写完buffer中的日志后,当触发了日志刷盘的几种规则时,会向redo log file on disk刷入重做日志,并在该文件中记下对应的LSN,暂且称之为redo_log_on_disk_lsn;
(4).数据页不可能永远只停留在内存中,在某些情况下,会触发checkpoint来将内存中的脏页(数据脏页和日志脏页)刷到磁盘,所以会在本次checkpoint脏页刷盘结束时,在redo log中记录checkpoint的LSN位置,暂且称之为checkpoint_lsn。
(5).要记录checkpoint所在位置很快,只需简单的设置一个标志即可,但是刷数据页并不一定很快,例如这一次checkpoint要刷入的数据页非常多。也就是说要刷入所有的数据页需要一定的时间来完成,中途刷入的每个数据页都会记下当前页所在的LSN,暂且称之为data_page_on_disk_lsn。
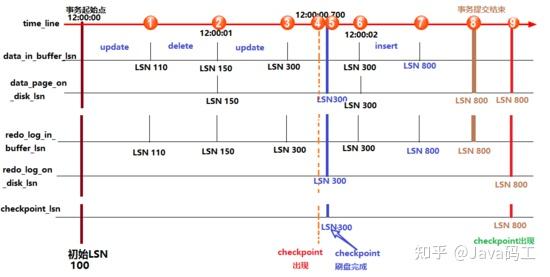
上图中,从上到下的横线分别代表:时间轴、buffer中数据页中记录的LSN(data_in_buffer_lsn)、磁盘中数据页中记录的LSN(data_page_on_disk_lsn)、buffer中重做日志记录的LSN(redo_log_in_buffer_lsn)、磁盘中重做日志文件中记录的LSN(redo_log_on_disk_lsn)以及检查点记录的LSN(checkpoint_lsn)。
假设在最初时(12:0:00)所有的日志页和数据页都完成了刷盘,也记录好了检查点的LSN,这时它们的LSN都是完全一致的。
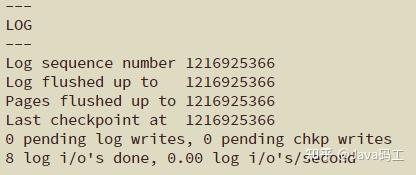
假设此时开启了一个事务,并立刻执行了一个update操作,执行完成后,buffer中的数据页和redo log都记录好了更新后的LSN值,假设为110。这时候如果执行 show engine innodb status 查看各LSN的值,即图中①处的位置状态,结果会是:
log sequence number(110) > log flushed up to(100) = pages flushed up to = last checkpoint at之后又执行了一个delete语句,LSN增长到150。等到12:00:01时,触发redo log刷盘的规则(其中有一个规则是
innodb_flush_log_at_timeout 控制的默认日志刷盘频率为1秒),这时redo log file on disk中的LSN会更新到和redo log in buffer的LSN一样,所以都等于150,这时 show engine innodb status ,即图中②的位置,结果将会是:
log sequence number(150) = log flushed up to > pages flushed up to(100) = last checkpoint at再之后,执行了一个update语句,缓存中的LSN将增长到300,即图中③的位置。
假设随后检查点出现,即图中④的位置,正如前面所说,检查点会触发数据页和日志页刷盘,但需要一定的时间来完成,所以在数据页刷盘还未完成时,检查点的LSN还是上一次检查点的LSN,但此时磁盘上数据页和日志页的LSN已经增长了,即:
log sequence number > log flushed up to 和 pages flushed up to > last checkpoint at但是log flushed up to和pages flushed up to的大小无法确定,因为日志刷盘可能快于数据刷盘,也可能等于,还可能是慢于。但是checkpoint机制有保护数据刷盘速度是慢于日志刷盘的:当数据刷盘速度超过日志刷盘时,将会暂时停止数据刷盘,等待日志刷盘进度超过数据刷盘。
等到数据页和日志页刷盘完毕,即到了位置⑤的时候,所有的LSN都等于300。
随着时间的推移到了12:00:02,即图中位置⑥,又触发了日志刷盘的规则,但此时buffer中的日志LSN和磁盘中的日志LSN是一致的,所以不执行日志刷盘,即此时 show engine innodb status 时各种lsn都相等。
随后执行了一个insert语句,假设buffer中的LSN增长到了800,即图中位置⑦。此时各种LSN的大小和位置①时一样。
随后执行了提交动作,即位置⑧。默认情况下,提交动作会触发日志刷盘,但不会触发数据刷盘,所以 show engine innodb status 的结果是:
log sequence number = log flushed up to > pages flushed up to = last checkpoint at最后随着时间的推移,检查点再次出现,即图中位置⑨。但是这次检查点不会触发日志刷盘,因为日志的LSN在检查点出现之前已经同步了。假设这次数据刷盘速度极快,快到一瞬间内完成而无法捕捉到状态的变化,这时 show engine innodb status 的结果将是各种LSN相等。
3.3 InnoDB的恢复行为



 发表于 2023-4-17 13:05:09
发表于 2023-4-17 13:05:09