|
|
LeNet-5是一个经典的深度卷积神经网络,由Yann LeCun在1998年提出,旨在解决手写数字识别问题,被认为是卷积神经网络的开创性工作之一。该网络是第一个被广泛应用于数字图像识别的神经网络之一,也是深度学习领域的里程碑之一。本文首先介绍了卷积神经网络的基本原理,然后介绍了LeNet-5的基本结构和训练过程,并给出了LeNet-5的pytorch代码实现,最后说明了LeNet-5对深度学习的贡献。
一、卷积神经网络基本原理
卷积神经网络主要由卷积层、池化层和全连接层三个部分构成。其中,卷积层是卷积神经网络的核心部分,它通过对输入图像进行卷积操作来提取图像的特征。卷积层的输入通常是一个多通道的(例如多通道图像),每个通道代表一个特征,卷积层的输出也是多通道的,其中每个通道表示一个不同的特征。
(1)填充、步长、通道数的概念
填充( Padding )是指在输入数据的边缘添加一定数量的像素,使得输出数据的尺寸能够与输入数据相匹配。也就是在矩阵的边界上填充一些值,以增加矩阵的大小,通常用 0 或者复制边界像素来进行填充。
步长(Stride)是指卷积核在每一次卷积操作中滑动的距离。步长的大小可以影响输出数据的大小,也可以影响特征提取能力和计算复杂度。当步长增大时,输出数据的尺寸会减小,特征提取能力会变弱,但计算速度会加快。
通道数(Channel)也称为深度或特征图数量,是指卷积神经网络中每一层输出的特征图数量。通道数的大小直接影响了卷积神经网络的特征提取能力和计算复杂度。通过增加通道数,可以增强卷积神经网络的特征提取能力,但也会增加计算复杂度。
(2)卷积层
卷积操作的实现可以使用滑动窗口的方式,即在输入图像上滑动一个卷积核,将卷积核和输入图像对应位置的像素值相乘并求和,得到输出图像中对应位置的像素值。对于多通道卷积,卷积核的通道数需要与输入数据的通道数相同,每个卷积核的每个通道都会与输入数据的相应通道进行卷积操作。在每次卷积操作中,卷积核会滑动到输入数据上的不同位置,与当前位置的数据进行卷积计算,得到一个输出值。例如在图2中输入图像尺寸为6\times6\times3 ,通道数为3,卷积核有两个,每个尺寸为3\times3\times3,通道数为3(与输入图像通道数一致),卷积时,仍是以滑动窗口的形式,从左至右,从上至下,3个通道的对应位置相乘求和,输出结果为 4\times4\times2 的特征图。

图1 单通道卷积计算示意
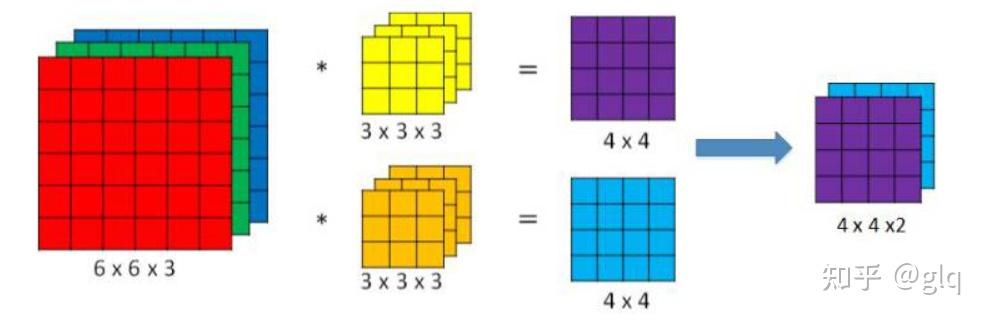
图2 多通道卷积
(3)池化层
池化层用于降低特征图的空间分辨率,并增强模型对输入图像的平移不变性和鲁棒性。常用的池化方式包括最大池化和平均池化。最大池化的操作是在一个滑动窗口中取最大值作为输出,平均池化的操作是在一个滑动窗口中取平均值作为输出。
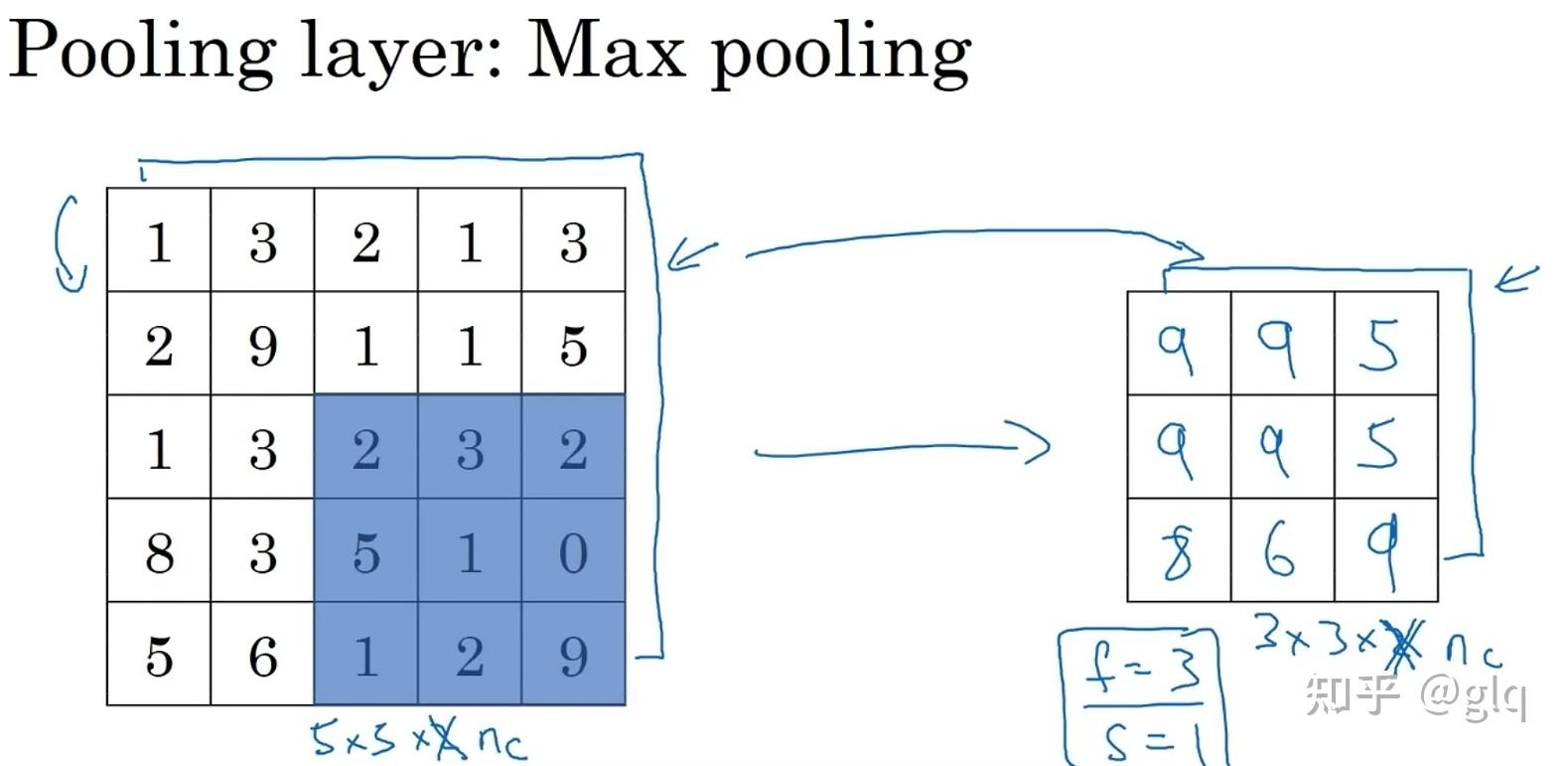
图3 最大池化
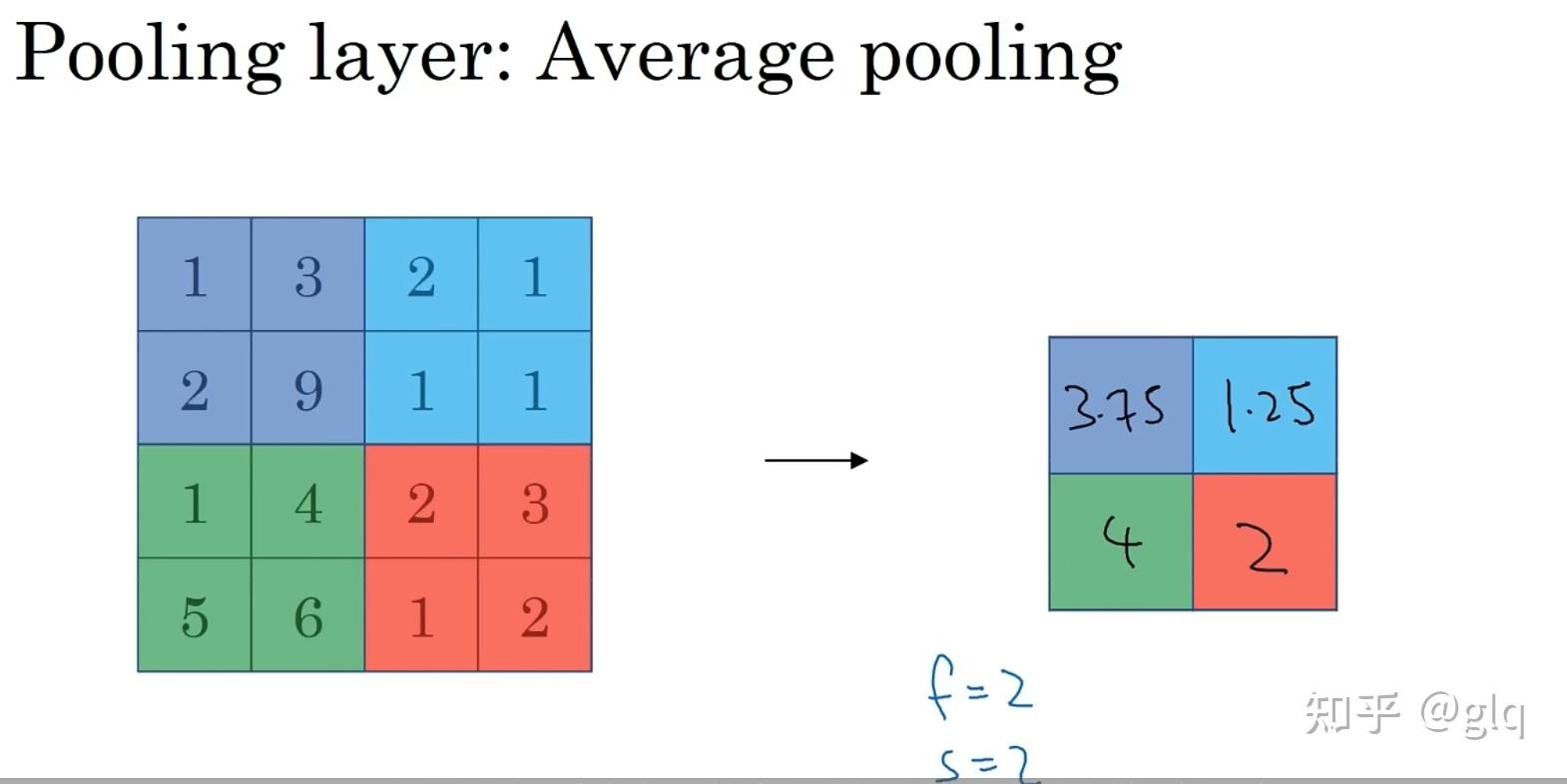
图4 平均值池化
(4)全连接层
全连接层通常用于将卷积层和池化层提取的特征进行分类或回归。它的输入是一维向量,其输出的维度与任务的分类数或回归值的维度相同。
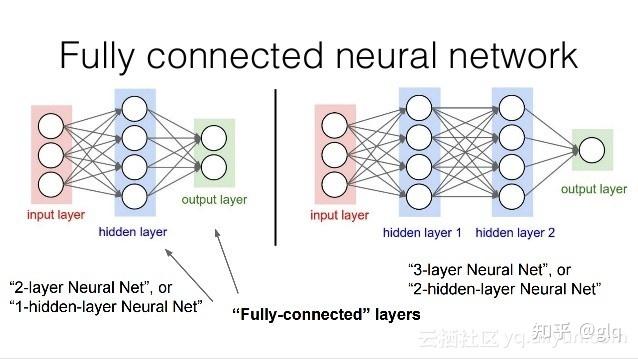
图5 全连接层
二、LeNet-5的基本结构
LeNet-5的基本结构包括7层网络结构(不含输入层),其中包括2个卷积层、2个降采样层(池化层)、2个全连接层和输出层。
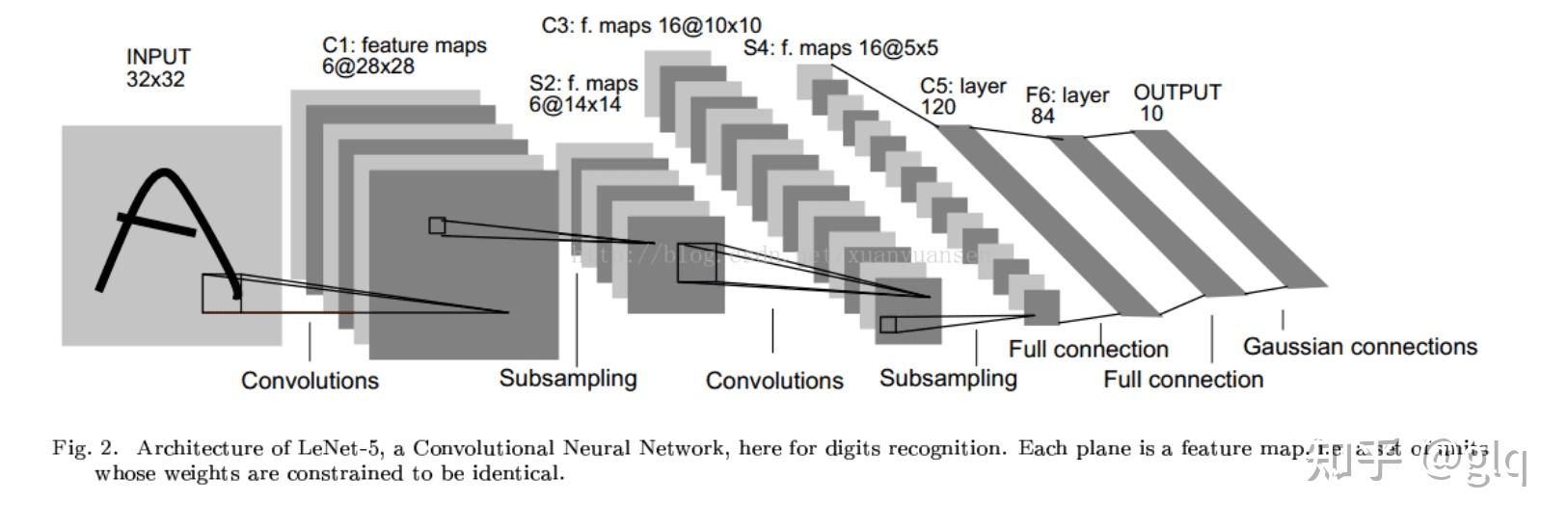
图6 LeNet-5基本结构
1、输入层(Input layer)
输入层接收大小为 32 \times 32 的手写数字图像,其中包括灰度值(0-255)。在实际应用中,我们通常会对输入图像进行预处理,例如对像素值进行归一化,以加快训练速度和提高模型的准确性。
2、卷积层C1(Convolutional layer C1)
卷积层C1包括6个卷积核,每个卷积核的大小为 5 \times 5 ,步长为1,填充为0。因此,每个卷积核会产生一个大小为 28 \times 28 的特征图(输出通道数为6)。
3、采样层S2(Subsampling layer S2)
采样层S2采用最大池化(max-pooling)操作,每个窗口的大小为 2 \times 2 ,步长为2。因此,每个池化操作会从4个相邻的特征图中选择最大值,产生一个大小为 14 \times 14 的特征图(输出通道数为6)。这样可以减少特征图的大小,提高计算效率,并且对于轻微的位置变化可以保持一定的不变性。
4、卷积层C3(Convolutional layer C3)
卷积层C3包括16个卷积核,每个卷积核的大小为 5 \times 5 ,步长为1,填充为0。因此,每个卷积核会产生一个大小为 10 \times 10 的特征图(输出通道数为16)。
5、采样层S4(Subsampling layer S4)
采样层S4采用最大池化操作,每个窗口的大小为 2 \times 2 ,步长为2。因此,每个池化操作会从4个相邻的特征图中选择最大值,产生一个大小为 5 \times 5 的特征图(输出通道数为16)。
6、全连接层C5(Fully connected layer C5)
C5将每个大小为 5 \times 5 的特征图拉成一个长度为400的向量,并通过一个带有120个神经元的全连接层进行连接。120是由LeNet-5的设计者根据实验得到的最佳值。
7、全连接层F6(Fully connected layer F6)
全连接层F6将120个神经元连接到84个神经元。
8、输出层(Output layer)
输出层由10个神经元组成,每个神经元对应0-9中的一个数字,并输出最终的分类结果。在训练过程中,使用交叉熵损失函数计算输出层的误差,并通过反向传播算法更新卷积核和全连接层的权重参数。
然而,在实际应用中,通常会对LeNet-5进行一些改进,例如增加网络深度、增加卷积核数量、添加正则化等方法,以进一步提高模型的准确性和泛化能力。
三、LeNet-5训练过程
LeNet-5的训练过程使用反向传播算法(BP算法),通过最小化误差函数(通常使用交叉熵损失函数)来优化网络的权重和偏置。网络的权重和偏置是通过随机初始化得到的,然后,网络通过反向传播算法不断地调整权重和偏置,使得误差函数最小化。
关于BP算法相关原理介绍可参考文章:https://cloud.tencent.com/developer/article/1450765。
四、基于pytorch的LeNet-5代码实现
1、定义LeNet-5模型
#加载库
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 定义LeNet-5模型
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1)
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(in_features=16 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=84)
self.fc3 = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.pool1(torch.relu(self.conv1(x)))
x = self.pool2(torch.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x2、加载MNIST数据集
这里选择采用MNIST手写数字识别数据集进行训练和测试。
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())
# 定义数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
# 定义模型、损失函数和优化器
model = LeNet5()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())3、训练模型
# 训练模型
for epoch in range(10):
for i, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, 10, i+1, len(train_loader), loss.item()))4、测试模型
在测试数据集上对模型进行测试,并打印输出测试正确率。
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test Accuracy: {:.2f}%'.format(100 * correct / total))四、浅谈LeNet-5贡献
LeNet-5在当时的手写数字识别任务中取得了很好的效果,可以达到98%以上的准确率,这是当时最先进的技术水平。它的成功证明了深度学习的潜力,吸引了更多研究者加入到深度学习的研究中。同时,LeNet-5也为后来更加复杂的卷积神经网络奠定了基础,例如AlexNet、VGG、ResNet等。这些网络都采用了类似LeNet-5的卷积神经网络结构,但增加了更多的层数和参数,从而在图像分类、目标检测等任务中取得了更好的效果。虽然LeNet-5在当今深度学习的发展中已经不再是最先进的技术,但它的经典结构和训练方法仍然对深度学习的发展和应用有重要意义。 |
|



 发表于 2023-7-16 18:16:59
发表于 2023-7-16 18:16:59