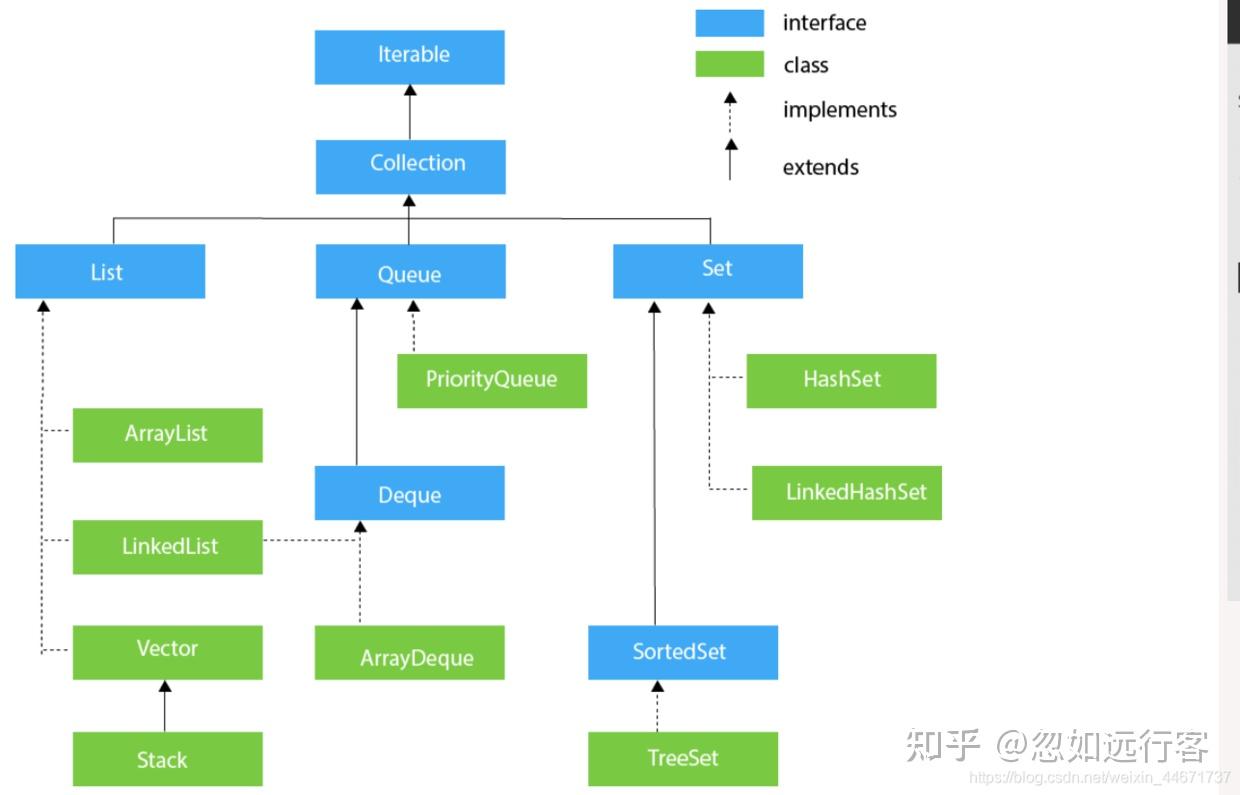
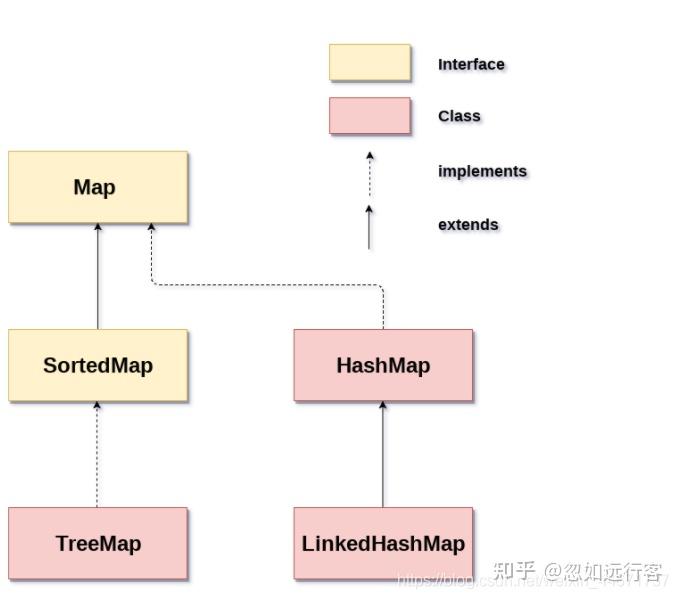
2
3
7
新手上路
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver手机版
Powered by Discuz! X3.4© 2001-2015 Comsenz Inc.



 发表于 2023-7-15 18:00:24
发表于 2023-7-15 18:00:24