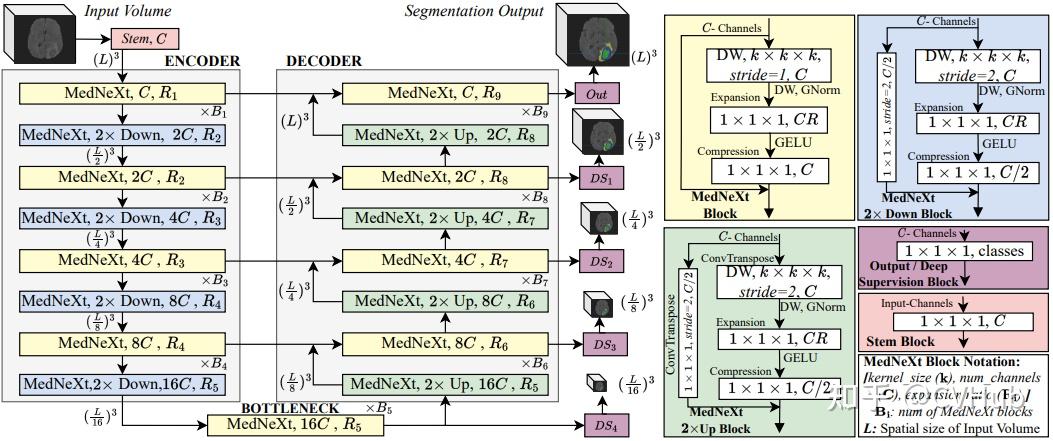
DW层主要包含一个卷积核大小为 k × k × k 的深度卷积,随后接上归一化,具有 C 个输出通道。此处,作者使用channel-wise GroupNorm来稳定较小BatchSize所带来的的潜在影响,而不是使用ConvNeXt或者说大部分Transformer架构中常用的LayerNorm。这是由于卷积的深度性质必将允许该层中的大卷积核复制Swin-Transformers的大注意力窗口,同时又能够有效的限制计算量。 Expansion Layer
对标Transformers的类似设计,扩展层主要用于通道缩放,其中 R 是扩展比,同时引入了GELU激活函数。需要注意的是,大的 R 值允许网络横向扩展,并采用 1 × 1 × 1 的卷积核限制计算量。因此,该层有效地将宽度缩放与上一层中的感受野进行了深度绑定。 Compression Layer
模块的最后便是采用具有 1 × 1 × 1 卷积核和 C 个输出通道的卷积层执行特征图的逐通道压缩。
总的来说,MedNeXt是基于纯卷积架构的,其保留了ConvNets固有的归纳偏置(inductive bias),可以更轻松地对稀疏医学数据集进行训练。此外,同ConvNeXt一样,为了更好的对整体网络架构进行伸缩和扩展,本文设计了一种 3 种正交类型的缩放策略,以针对不同数据集实现更有效和鲁邦的医学图像分割性能。 Resampling with Residual Inverted Bottlenecks
最初的ConvNeXt架构利用由标准步长卷积组成的独立下采样层。与之相反的便是应用转置卷积来进行上采样操作。然而,这种朴素的设计并未能充分该架构的优势。因此,本文通过将倒置的瓶颈层扩展到MedNeXt中的重采样块来改进这一点。
具体实现上,可以通过在第一个DW层中分别插入步长卷积或转置卷积来完成,以实现可以完成上、下采样的MedNeXt块,如上图绿色和蓝色部分所示。此外,为了使梯度流更容易,作者添加了具有 1 × 1 × 1 卷积或步长为 2 的转置卷积的残差连接。如此一来。便可以充分利用类似 Transformer 的倒置瓶颈的优势,以更低的计算代价保留更丰富的语义信息和所需的空间分辨率,这非常有利于密集预测型的医学图像分割任务。 UpKern: Large Kernel Convolutions without Saturation
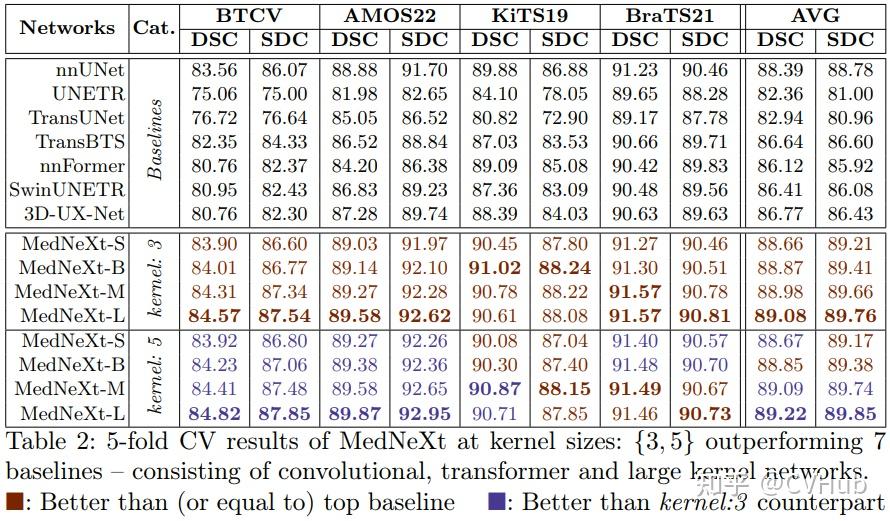
大家都知道,提高卷积核的大小意味着增大网络的感受野从而有效提升网络的性能。然而,需要注意的是,这仅仅是理论感受野,而非实际感受野。So sad~~~
因此,最近有许多工作都在探索大卷积核的魔力,据笔者有限的知识储备,目前看到过最高的极限是扩展到61 x 61,有兴趣的读者可以自行去翻阅『CVHub』。讨论回ConvNeXt本身,其卷积核的极限只到7 x 7,根据原著所述再往上增大就“饱和”了。所以,针对医学图像分割这类本身数据就很稀缺的任务来说,如何才能有效的应用和发挥该架构的优势呢?下面看看作者是如何做的。
为了解决这个问题,作者们首先借鉴了Swin Transformer V2的灵感,其中一个大的注意力窗口网络是用另一个较小的注意力窗口训练的网络进行初始化的。此外,作者提议将现有的偏差矩阵空间插值到更大的尺寸作为预训练步骤,而不是从头开始训练,后续的实验也充分验证了此方法的有效性。
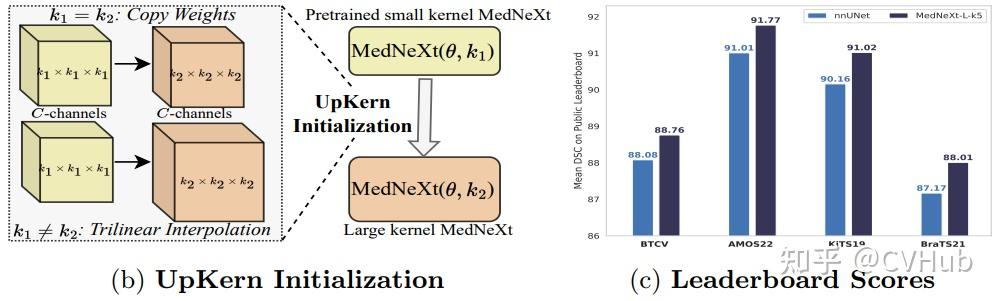
Upsampled Kernel (UpKern) & Performance
如上图所示,作者对针对卷积核进行了相应的“定制化”,以克服性能饱和问题。其中,UpKern允许我们通过对大小不兼容的卷积核(表示为张量)进行三维线性上采样来初始化具有兼容的预训练小卷积核网络的大卷积核网络,从而迭代地增加卷积核大小。所有其他具有相同张量大小的层(包括归一化层)都通过复制未更改的预训练权重来初始化。
综上所述,以上操作为 MedNeXt 带来了一种简单但有效的初始化技术,可帮助大卷积核网络克服医学图像分割常见的相对有限的数据场景中的性能饱和。 Compound Scaling of Depth, Width and Receptive Field



 发表于 2023-7-15 17:45:20
发表于 2023-7-15 17:45:20