|
|
Res2Net: A New Multi-scale Backbone Architecture, Shang-Hua Gao#, Ming-Ming Cheng*#, Kai Zhao, Xin-Yu Zhang, Ming-Hsuan Yang, Philip Torr, IEEE TPAMI, 43(2):652-662, 2021. [pdf | code | project |PPT | bib | 中译版 | LaTeX] [中国百篇最具影响国际学术论文]

这篇关于多尺度特征表达的论文引用最近超过了1300多次,被很多国际同行广泛使用,在部分领域(例如鲁棒性,泛化性研究)的优越性能也超乎了我们自己的预期。因此,我想在这个时候把相关的介绍分享出来。

多尺度信息在几乎所有视觉任务中都至关重要。我们先来看一个例子。这里我展示了一个图像中某个目标物体的全部信息。不知道大家是否能看出来这是什么物体?是一个树桩吗?

当我们看到整张图像的时候,我们很确信这个物体是一个长得像树桩的凳子。人类之所以能够非常快速鲁棒的感知视觉信息,就是因为我们非常善于利用视觉信号中的多尺度信息。对于几乎所有的计算机视觉任务,多尺度信息的高效建模都至关重要。例如,对于语义分割来讲,我们需要局部细节信息确定物体边界,需要整个物体级的信息识别物体类别,甚至有时候需要更大范围的周围环境信息才能做出鲁棒的判断。除了语义分割,目标检测、实例分割、目标跟踪等几乎所有视觉任务都需要强大的多尺度信息建模能力。

卷积神经网络已经在计算机视觉的几乎所有分支领域都替代了传统方法。以大家比较熟悉的VGG网络为例,卷积神经网络相对传统方法最大的优势就是可以自动地学习多尺度信息。对图像特征不断进行卷积和Pooling的过程,也是自动地学习更大尺度特征的过程。越靠后的卷积层的特征对应的感受野也越大,对应更大尺度的特征。如果我们随便选一层,问大家这层卷积特征对应原图中最大的感受野有多大。很多人都可以快速算出来。这一方面说明了大家对VGG网络很熟悉。另一方面也说明了VGG网络中的每一层特征对应的尺度相对比较单一。这种多尺度表示能力的匮乏性和我们之前分析的几乎所有的计算机视觉任务在决策过程中都需要丰富的多尺度信息相矛盾。这种多尺度表征能力的不足,限制了VGG网络取得更好的性能。

CVPR 2016年最佳论文ResNet很好的改进了VGG网络多尺度表达能力不足的问题。虽然ResNet论文中的分析是从函数拟合的角度进行分析的。我们也可以从另一个角度去理解ResNet网络。当输入特征x经过卷积层之后,其输出特征F(x)具有比x更大的感受野。如果x通过跳层链接直接输出,则感受野不变。也就是说ResNet的一个单元可以支持2种不同的等效感受野变化。当我们用n个ResNet单元组合在一起的时候,就有2的n次方中不同的感受野大小组合,因而具有更强的多尺度表达能力。这也就从多尺度特征表达的角度揭示了ResNet全面优于VGG网络的原因。如果从这个角度去观察,CVPR 2017年的最佳论文DenseNet则通过更多的跳层链接进一步增强了多尺度表达的能力。
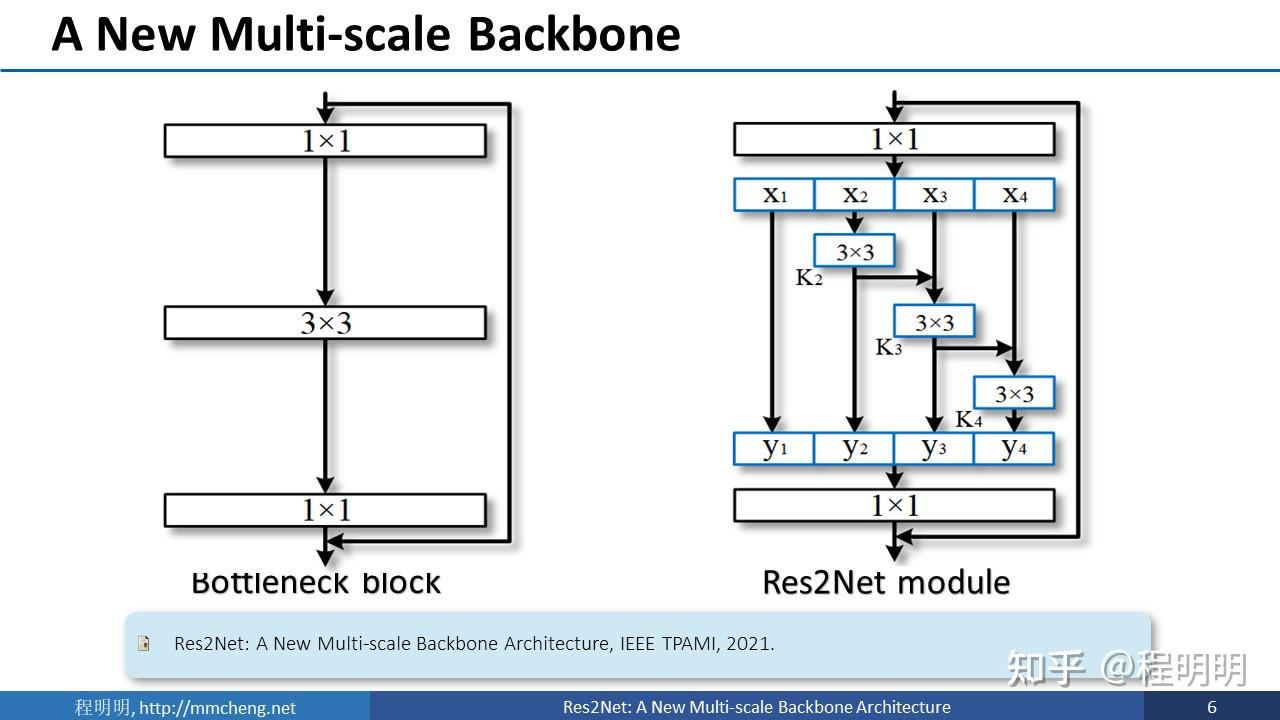
我们的方法从卷积神经网络中的最基本的常用单元入手。我们对于主流卷积神经网络中广泛存在的残差瓶颈结构进行多尺度增强。如右图所示,对于输入特征,我们首先通过1x1卷积进行通道数的调控。然后将这些特征分为4份。例如,x2可以经过一次卷积直接输出,其卷积结果可以进一步和x3相加再经过一次卷积后输出。这种做法的优势显而易见。比如说,输出y4可以是x4经过一次卷积,也可以是x3经过2次卷积,还可以是x2经过三次卷积。这种操作使得尺度种类组合爆炸,进而提供非常丰富的多尺度特征。虽然右侧的图看着更复杂,但是采用这种方式提升多尺度能力,仅需要增加十多行代码。而且,右侧的模块计算量和参数量小于左侧。左侧图中计算量最大的是3x3卷积。假如我们有512个通道,这里的计算量是512x3x3x512。像右图所示的分为四份之后,每一个3x3的卷积仅需要左侧1/16的计算量。因此,如果简单的分割为4块而不大幅增加通道数,右侧的计算量只有左侧的不到1/4。
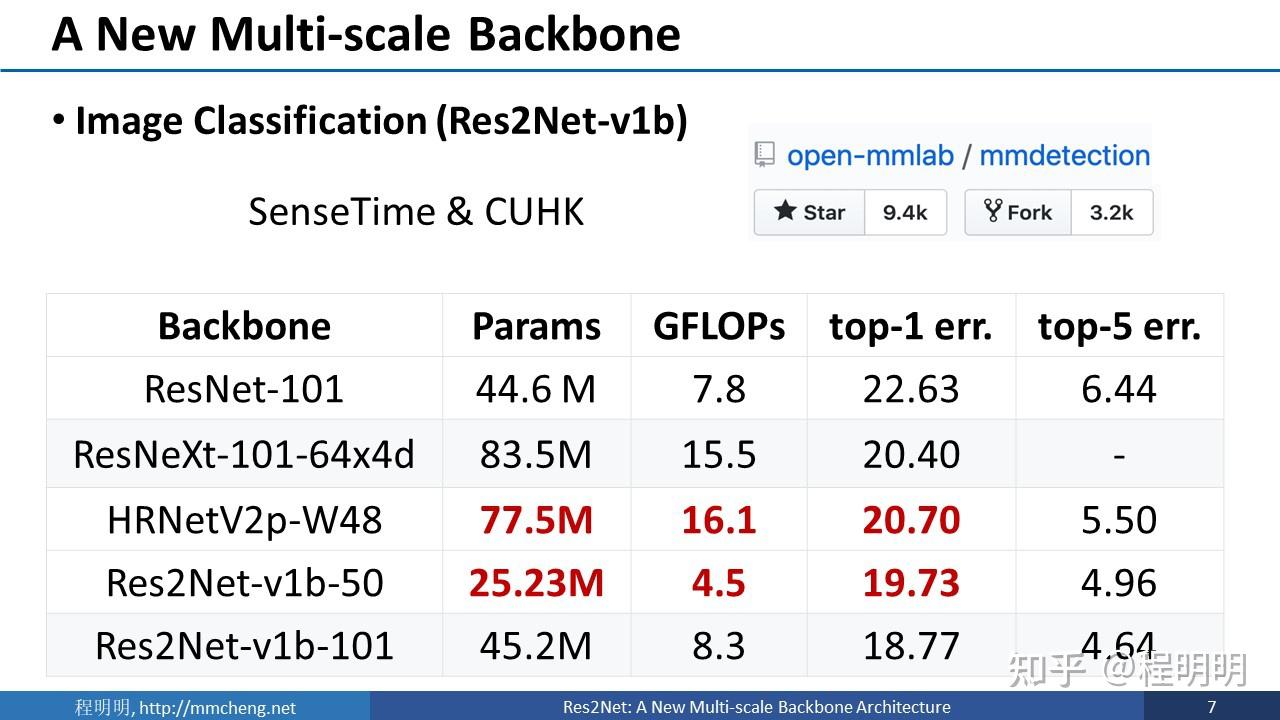
虽然该方法很简单。但是这种增强的多尺度表征在很多任务上取得了优异的性能提升。以分类任务为例,我们在mmdetection上进行了对比实验。该benchmark是由商汤科技和香港中文联合牵头维护的一个优化程度非常高的函数库。与之前在该benchmark上长时间排名榜首的微软公司的HRNet相比,我们的方法仅需要1/3左右的参数量和1/4左右的计算量就可以取得更好的性能,识别错误率更低。

在物体检测任务上,我们的方法也超越了之前最好的方法HRNet。这里的参数量和计算量的节省幅度并没有分类任务那么大,一个重要原因是我们的方法只有特征提取骨干网络有所节省,其余部分和HRNet保持一致。

我们也在MS-COCO数据集上用Mask RCNN方法做了实验。
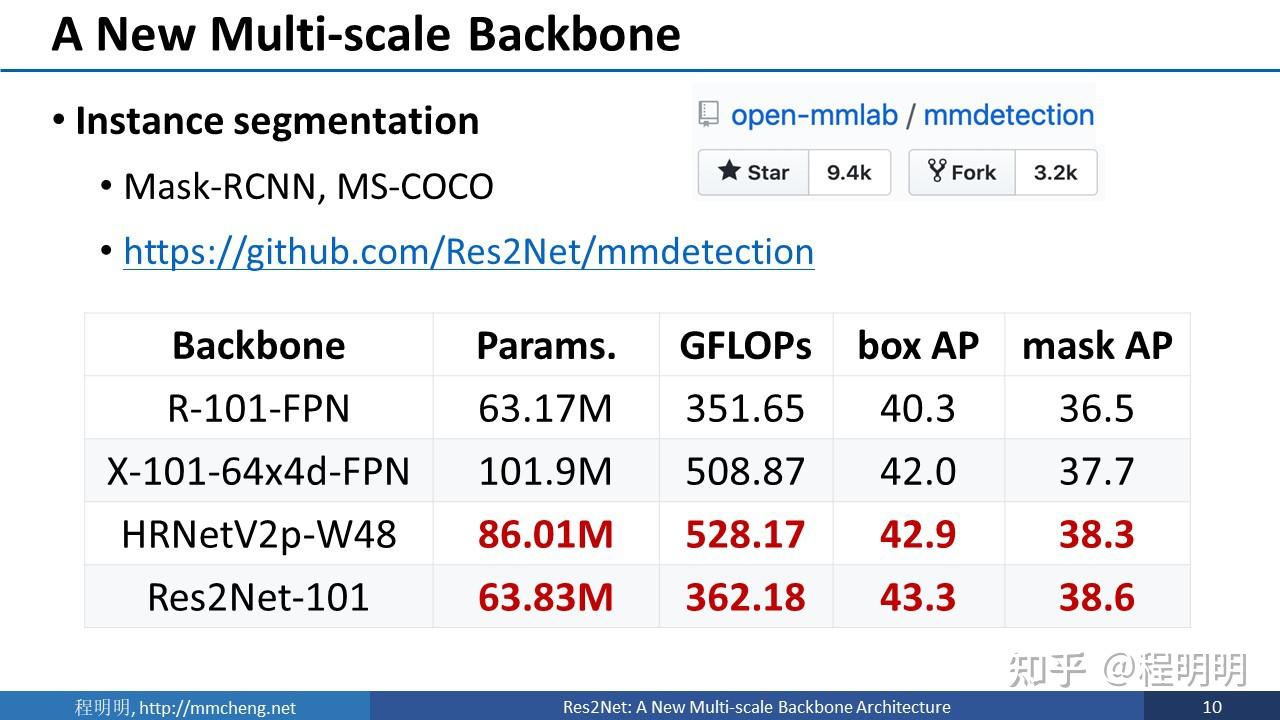
采用我们的Res2Net提取特征,可以在更低的参数量,更少的计算量前提下获得更好的性能。

我们的方法在TPAMI期刊审稿的过程中,有一个匿名审稿人非常负责。审稿人用自己实现的我们的方法来解决Pose Estimation问题,发现性能非常好。因此,我们也按照审稿人的建议,在后续的实验里面加入了姿态估计实验。
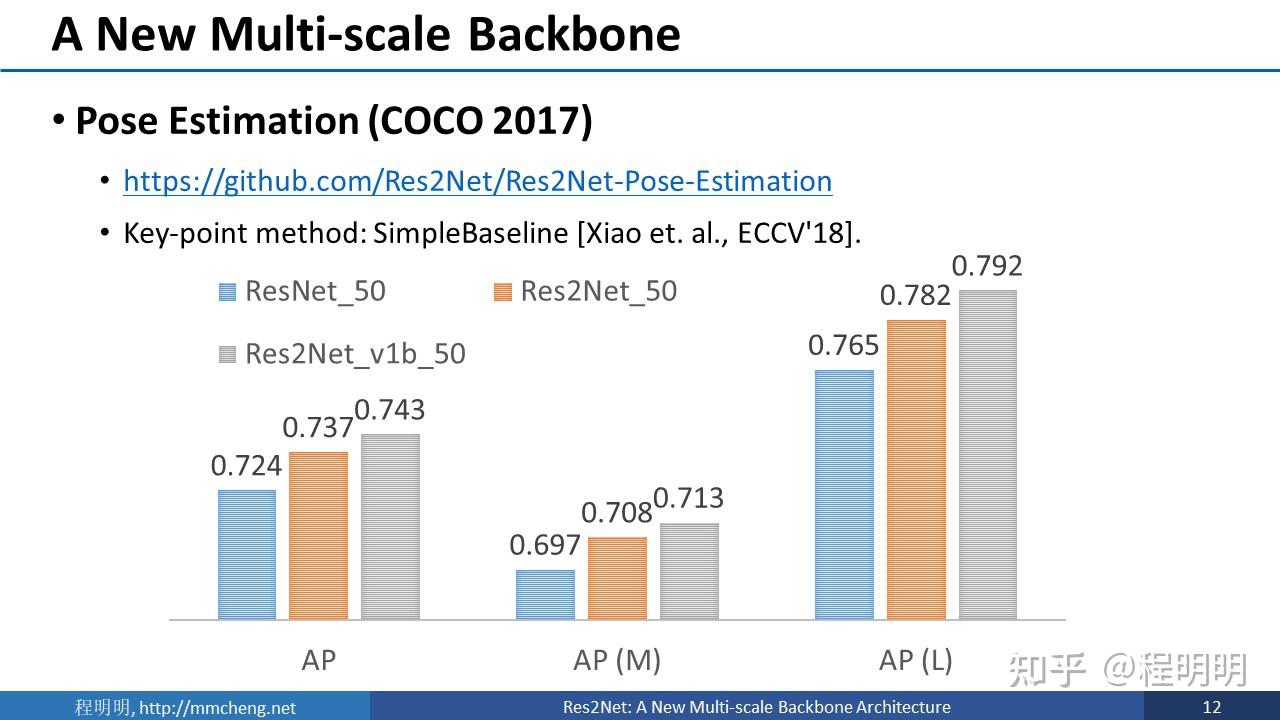
这张图展示了使用不同backbone模型进行姿态估计的性能对比。我们的方法相对于ResNet有大幅的提升。

在全景分割任务中,我们在detectron2 benchmark上进行了对比实验。

Detectron2是Facebook AI research推出的下一代软件系统,系统优化非常到位。我们的方法相比默认的baseline也有着大幅的提升。

Res2net 的残差递进多尺度表征看似并行度受到影响。但是实际影响并不太大。即使是ResNet,看似是一组3x3卷积并行执行,但是由于普通GPU的CUDA核心有限,其实也是一组执行之后再执行下一组的。我们的Res2Net默认只有4个分组,因而大多数情况下几乎所有CUDA核心都充分利用而很少因为串行操作而等待,实际执行速度也很快。此外,有一些细粒度优化很好的平台如清华的Jittor框架下效率会更高。右图展示了我们的方法和同期的性能比较强大的方法的性能和实际执行效率的对比。

自从我们的方法正式发表以后,被众多研究者应用于道路检测,医疗影像分析,交互式分割,行人重识别,类别激活图预测,深度估计等计算机视觉任务并取得了明显的性能提升。此外,相关技术也被其他研究者应用于语音分析,蛋白质结构预测等领域。这些领域的成功应用,表明多尺度建模能力不但对视觉任务非常重要,对于其他领域也很重要。

近期,我们的方法也被Beckley的Hendrycks博士及ACM Fellow Dawn Song应用于自然对抗样本和分布外泛化能力的研究。他们的实验结果表明,我们的方法能够大幅提升鲁棒性和泛化性。

多尺度能力对于几乎所有计算机视觉任务都至关重要。Res2net提供了一种简单的不用增加计算量和参数量的多尺度增强方法。在提升性能的同时,更强大的多尺度能力也可以提升视觉任务的鲁棒性和泛化性。 |
|



 发表于 2023-4-10 08:59:27
发表于 2023-4-10 08:59:27