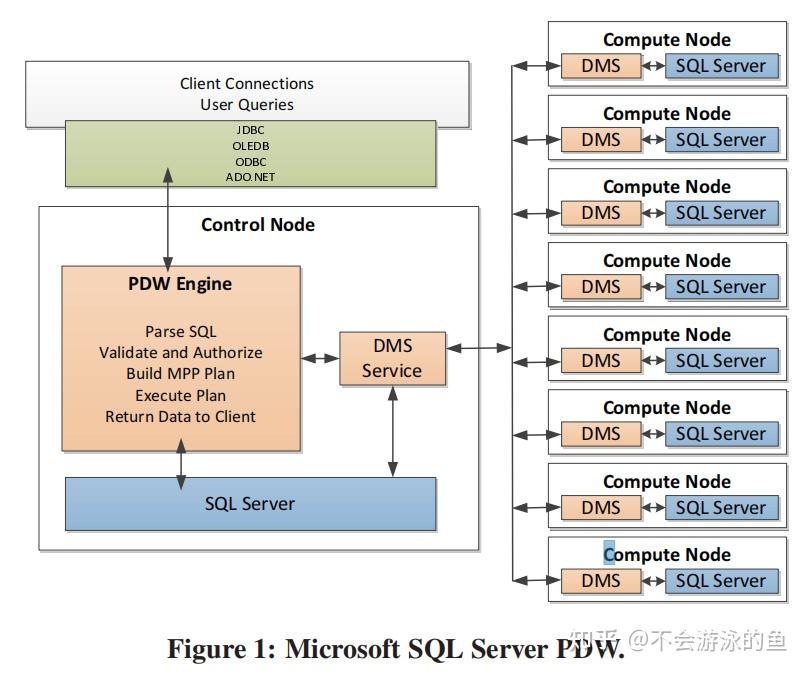
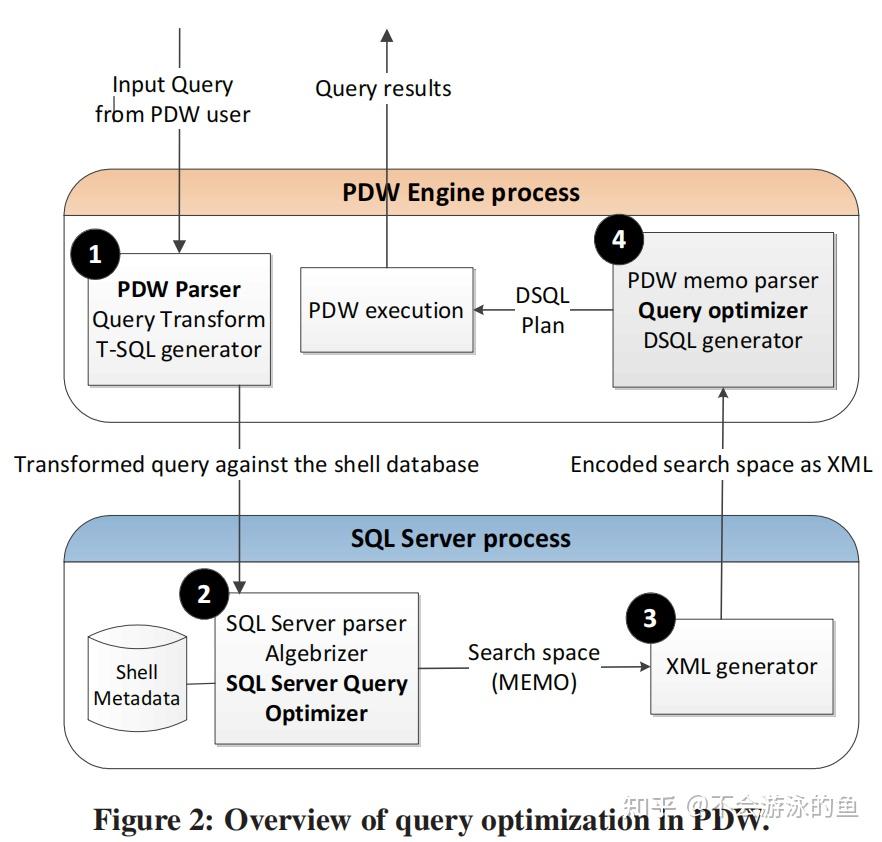
PDW QO是paper描述了SQL Server MPP查询优化器的设计与实现,Paralled Data Warehouse产品的查询优化器(PDW QO)。PDW QO是基于SQL Server单机Cascade优化器技术实现的针对分布式查询的CBO优化器。PDW QO在控制节点采用两阶段方式制定DPlan(分布式执行计划):
1.基于shell database中存储的全局metadata + 统计信息等,完成单机执行计划的优化
1.a PWD Parser,负责将query string转换为AST
1.b SQL Server Compilation,input为基于AST转换的operator tree
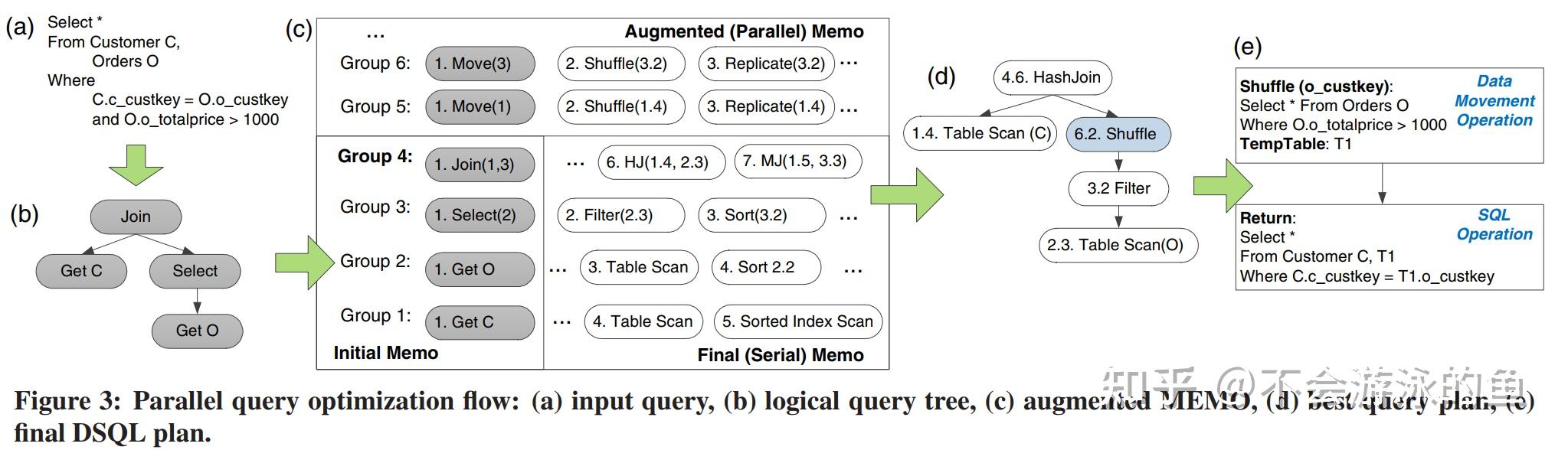
1.b.1 化简input operator tree,其实就是对于经过AST转换的operator tree,基于RBO规则进行转换,生成一个更优的operator tree,作为init plan存储到MEMO中,用于后续的等价变换,如果不理解MEMO的话,可以读下cascade的论文。
1.b.2 对于init plan,基于关系代数规则,进行等价变换,生成多个等价plans,join reorder也是在这个阶段进行
1.b.3 基于用shell database中存储的全局metadata + 统计信息等,完成单机执行计划的优化,生成可能的winner memo,会根据表的大小和列的统计值,评估等价plans的代价
1.b.4 apply physical implementation,为算子枚举物理执行方式,计算相应代价并做一些基本的剪枝
2.基于步骤1中的单机可能winner的plans,结合数据的分布信息,制定最佳分布式执行计划
2.a XML Generator,将步骤1输出的MEMO进行xml序列化
2. PDW Query Optimizer,memo中包含多个等价plans,并从单机统计信息角度计算了代价,这里枚举计算节点的数据分发方式,并计算分发代价,更新整个plan的代价信息,选择最佳 Data Movement
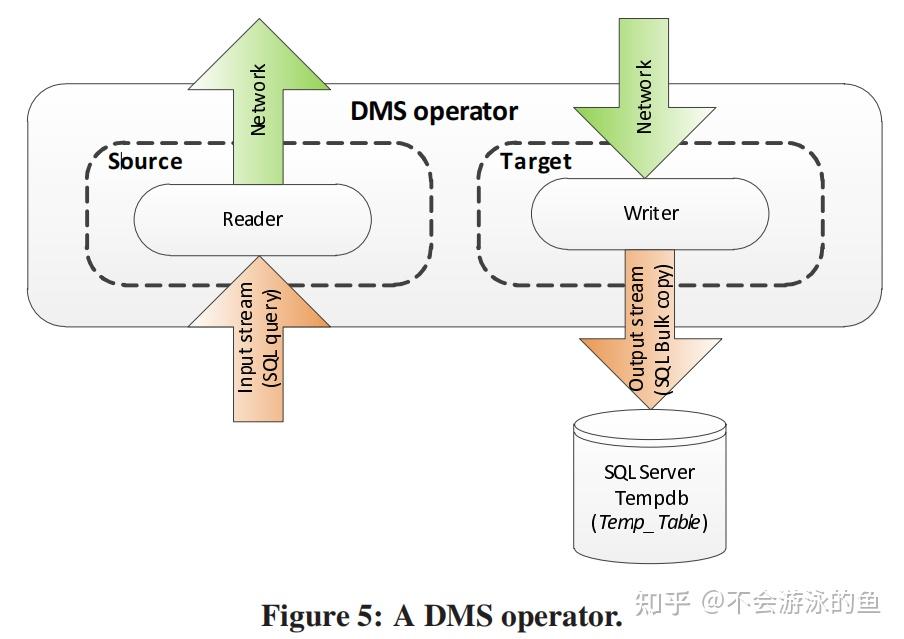
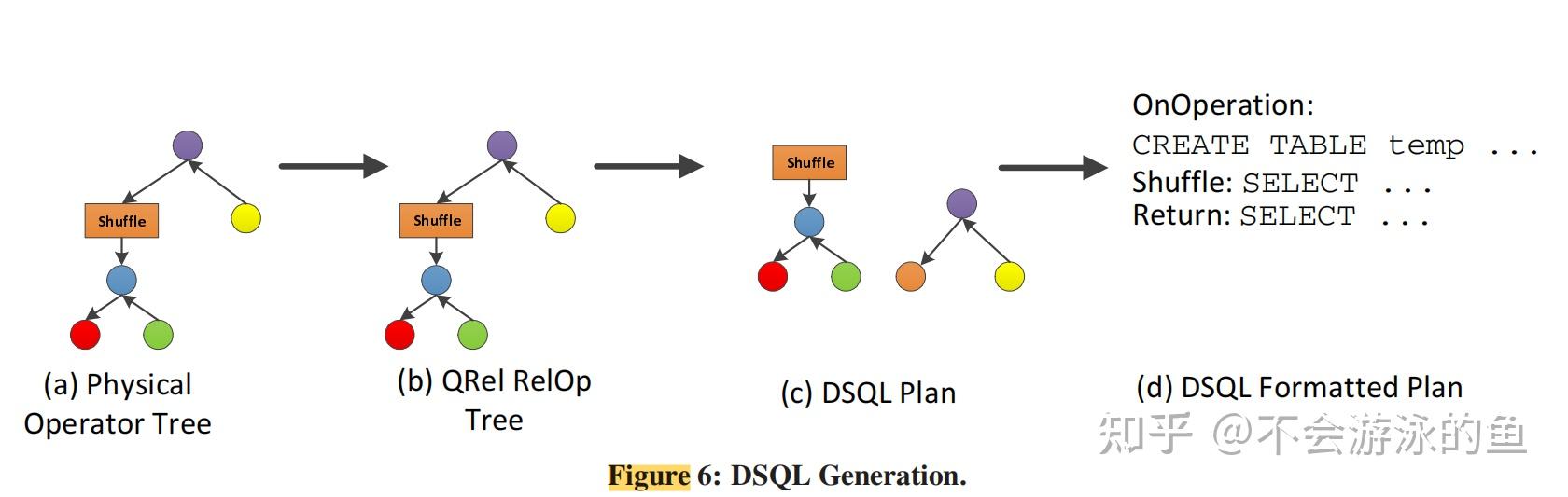
Data Movement Service(DMS)负责在所有node节点间转移数据。query在控制节点和数据节点上分布式执行时,就会需要在节点间移动数据。PDW使用临时表存储中间计算结果、接受其他节点发送的数据。在某些情况下,可以通过query重写的方式,将其下发到计算节点,然后将结果直接返回给客户端,此时,不需要走DMS了。个人理解:根据元数据,确认query涉及的数据在计算节点1上,那么改写query,增加query执行节点信息,然后下发,在计算节点1上执行,结果返回给客户端,不用建立临时表了。 DSQL plan的算子



 发表于 2023-4-9 08:08:40
发表于 2023-4-9 08:08:40