|
|
一、SQL简介
SQL 是用于访问和处理数据库的标准的计算机语言。SQL 是一门 ANSI 的标准计算机语言,用来访问和操作数据库系统。SQL 语句用于取回和更新数据库中的数据。SQL 可与数据库程序协同工作,比如 MS Access、DB2、Informix、MS SQL Server、Oracle、Sybase 以及其他数据库系统。
SQL对大小写不敏感。
二、SQL术语
1.数据库组成
一个数据库通常包含一个或多个表。每个表由一个名字标识(例如“客户”或者“订单”)。表的行称为记录,表会包含列名,类似python中的数据框。
2.SQL组成
可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。
SQL (结构化查询语言)是用于执行查询的语法。但是 SQL 语言也包含用于更新、插入和删除记录的语法。
查询和更新指令构成了 SQL 的 DML 部分:
- SELECT - 从数据库表中获取数据
- UPDATE - 更新数据库表中的数据
- DELETE - 从数据库表中删除数据
- INSERT INTO - 向数据库表中插入数据
SQL 的数据定义语言 (DDL) 部分使我们有能力创建或删除表格。我们也可以定义索引(键),规定表之间的链接,以及施加表间的约束。
SQL 中最重要的 DDL 语句:
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
SQL中的数据类型:
三、SQL语法
USE 数据库名---选择数据库,每一句话写完以后句尾要加上分号。
--相当于#,起到注释作用。
1.选取列
| select 列名 from 表名 | 选取表的一列 | | select 列名1,列名2 from 表名 | 选取表的多列 | | select * from 表名 | 选取表的所有列 |
Remark: 1.选取列的过程中可以通过别名的方式加入新列
select *,col1*col2 as new_col
from table
#最后会把前两列的乘积作为第三列Remark:2. select 后面跟常数or字符时产生全为该常数or字符的列
select id,label,1,"A" from ex1
id label 1 A
1 A 1 A
2 B 1 A
3 C 1 A
#as可以给常数or字符的列命名
select id,label,1 as status,"A" as name
from ex1
id label status name
1 A 1 A
2 B 1 A
3 C 1 A
2.选取列并去除重复值
select distinct 列名 from 表名
3.条件选择列
select 列名 from 表名 where 列名 运算符 值,where后面的条件成立时才会输出记录。
where语句中的运算符如下:
| = | 等号 | | <>,有时可用!= | 不等号 | | > | 大于 | | < | 小于 | | >= | 大于等于 | | <= | 小于等于 | | between | 取值在某个范围 | | like | 搜索某种模式 | | and | 逻辑与,连接where后的两句话 | | or | 逻辑或,连接where后的两句话 | | is null | 为空值 | | is not null | 不为空值 |
Remark:1. and执行的优先级会比or高。 2.where not condition会返回条件不成立的记录。
3.算数运算的优先级会大于逻辑运算符
4.指定列排序
order by 一般跟在where之后,表示先选后排。
| SELECT 列名1,列名2 FROM 表名 ORDER BY 列名1,列名2 | 优先按照第一列的升序排列表格,第一列相同时按第二列升序排列 | | SELECT 列名1,列名2 FROM 表名 ORDER BY 列名1 DESC,列名2 ASC | 按照第一列降序排列,第二列升序排列 |
5.插入新行
insert into 表名 values (数据1,数据2,......),其中数据1,数据2为某一行的行值,新的行会插入到数据的最后
例如:表格为3行5列时,则values后面的括号中包含5个数据。
Remark: 对于AUTO_INCREMENT和含有默认值的列可以用DEFAULT关键字,对于可以使用空值的列可以用NULL关键字赋值。
6.指定列插入新行
insert into 表名(列名1,列名2,.....) values (数据1,数据2,......),数据1和数据2等为插入到对应列的列值,未指定的列元素为空。
7.插入多行
insert into 表名 values (第一行数据1,第一行数据2,......),(第二行数据1,第二行数据2,......),.......
8.更新数据
UPDATE 表名称 SET 列名1 = 新值1,列名2=新值2 WHERE 列名3= 某值3
列名3= 某值3的所在行进行修改操作,将第一列改为新值1,列名2改为新值2。
Remark:更新多行数据时将where语句表示范围更宽泛即可
UPDATE salary
SET
sex =
CASE sex
WHEN &#39;m&#39; THEN &#39;f&#39;
ELSE &#39;m&#39;
END;
#update和case的连用
update salary set sex = if(sex = &#39;m&#39;,&#39;f&#39;,&#39;m&#39;)
#update和if连用9.删除行
DELETE FROM 表名称 WHERE condition---删除满足condition的所有行。
DELETE FROM 表名---删除所有行
10.选取列时指定选取的行数
select top 行数 列名 from 表名----选取该列的前几行
select top x percent 列名 from 表名----选取该列的前百分之x
select 列名 from 表名 limit 行数----选取该列的前几行
select 列名 from 表名 limit M,N----跳过前M行后选取N行
Remark: limit语句一定放在order 和where语句之后
11.like操作符
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
SELECT 列名 FROM 表名 WHERE 列名 LIKE ‘pattern’,其中where子句中常用的pattern如下表所示:
| N% | 表示以N开头的字符 | | %N | 表示以N结尾的字符 | | %N% | 表示包含N的字符 | | SELECT 列名 FROM 表名 WHERE 列名 NOT LIKE pattern | like前面加入not表示否定 |
pattern中的常用通配符:
| % | 表示一个或多个任意字符 | | _ | 表示一个任意字符 | | [ABC] | 表示ABC中的任意一个字符 | | [!ABC]or[^ABC] | 表示不在ABC中的任意字符 | | [A-M] | 表示在A—M之间的任意一个字符 |
http://12.in操作符
select 列名 from 表名 where 列名 in (value1, value2,.....)---选择的列名在value1,value2
13.between操作符
操作符 BETWEEN ... AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
select 列名 from 表名 where 列名 between value1 and value2 在此范围
select 列名 from 表名 where 列名 not between value1 and value2 不在此范围
14.从多个表中取数据
select 表1.列名,表2.列名 from 表1,表2 where 表1.列名=value1 and 表2.列名=value2
15.别名
SELECT 列名FROM 表名AS 表别名
SELECT 列名 AS 列别名 FROM 表名
16.多个表格信息合并
| 返回两个表的主键交集 | select 表1.列名,表2.列名 from 表1 (inner)join 表2 on
表1.主键=表2.主键 | | 主键不匹配时也返回左表所有行 | select 表1.列名,表2.列名 from 表1 left join 表2 on
表1.主键=表2.主键 | | 主键不匹配时也返回右表所有行 | select 表1.列名,表2.列名 from 表1 right join 表2 on
表1.主键=表2.主键 | | 主键不匹配时也返回两个表所有行 | select 表1.列名,表2.列名 from 表1 full join 表2 on
表1.主键=表2.主键 |
17.多个表按行合并(具有相同的列时)
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2union会把两个表中的某一列按行合并,并去掉重复值,最后的列名按照前一个查询的列确定。
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2union all 会把两个表中的某一列按行合并,保留重复值,最后的列名按照前一个查询的列确定。
18.选取数据加入新表/新数据库
SELECT 列名 INTO 新表名 (IN 新数据库)FROM 旧表名
19.创建数据库
create database 数据库名
20.创建空表格
create table 表名
(
列名1 数据类型1,
列名2 数据类型2,
....
)常见的数据类型如下:

20.表格复制
create table 新表名 as select * from 旧表名-----将旧表的所有信息复制到新表。
21.表格约束
表格约束通常在创建表格时加入到数据类型的后面。
常见的约束类型如下:
| NOT NULL | 新表格加入的数据非空 | | UNIQUE | 新表格加入的数据不重复 | | PRIMARY KEY | 表的主键,每个表有且仅有一个主键,主键的值唯一且不为空 | | FOREIGN KEY REFERENCES 表名1(主键1) | 外键foreign key指向其他表的主键,references表示指向的表和其主键 | | CHECK(取值范围) | check限制该列的取值范围 | | DEFAULT(默认值) | 该列为空时会加入默认值 | | AUTO_INCREMENT | AUTO_INCREMENT 关键字来执行 auto-increment 任务。在添加新行时,自动为主键赋值。
默认地,AUTO_INCREMENT 的开始值是 1,每条新记录递增 1。 |
22.drop
| DROP TABLE 表名 | 删除表格 | | DROP DATABASE 数据库名 | 删除数据库 | | TRUNCATE TABLE 表名称 | 清空表格数据 | | ALTER TABLE 表名 DROP INDEX 索引名 | 删除表格索引 | | ALTER TABLE 表名 DROP FOREIGN KEY 外键名 | 删除外键 | | ALTER TABLE 表名 DROP PRIMARY KEY | 删除主键 |
23.alter
| ALTER TABLE 表名 DROP COLUMN 列名 | 删除列 | | ALTER TABLE 表名 ADD 列名 列的数据类型 | 添加新列,并指定数据类型 | | ALTER TABLE 表名 ALTER COLUMN 列名 列的新数据类型 | 改变列的数据类型 | | ALTER TABLE 表名 AUTO_INCREMENT=初始值 | 改变主键的初始值 |
24.时间数据
| DATE | YYYY-MM-DD | | DATETIME | YYYY-MM-DD HH:MM:SS | | YEAR | YYYY |
25.正则表达式
regexp主要起到搜索作用,具体使用如下所示:
| select * from 表名 where 列名 regexp &#34;abc&#34; | 返回包含abc的记录 | | select * from 表名 where 列名 regexp &#34;^abc&#34; | 返回以abc开头的记录 | | select * from 表名 where 列名 regexp &#34;abc$&#34; | 返回以abc结尾的记录 | | select * from 表名 where 列名 regexp &#34;abc|abc$&#34; | 返回包含abc或者以abc结尾的记录 |
26. 复合主键
当表中不存在单一的一列值来区分每一个记录时,可以使用多列的方式形成一个复合主键,用来区分每一个记录。例如如下所示的表格不存在单一主键,可以用两列结合的方式形成复合主键。
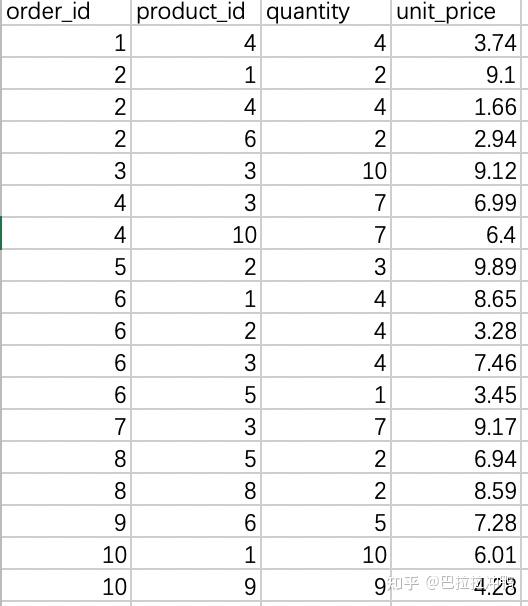
27. group by
select * from table group by 列1,列2,.....----按照指定列对表格进行分块排序
REMARK:group by 和 order by 一起使用时,会先使用group by 分组,并取出分组后的第一条数据,所以后面的order by 排序时根据取出来的第一条数据来排序的,但是第一条数据不一定是分组里面的最大数据。group by 比order by先执行,order by不会对group by 内部进行排序,如果group by后只有一条记录,那么order by 将无效。
28.group_concat---按组合并
group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator &#39;分隔符&#39;] ), group _concat主要配合group by 函数进行分组,并将分组后的内容整合起来输出。分隔符默认为逗号
|id |subject |student|teacher|score|
|1 |数学 |小红 |王老师 |80 |
|2 |数学 |小李 |王老师 |80 |
|3 |数学 |小王 |王老师 |70 |
|4 |数学 |小张 |王老师 |90 |
|5 |数学 |小赵 |王老师 |70 |
|6 |数学 |小孙 |王老师 |80 |
|7 |数学 |小钱 |王老师 |90 |
|8 |数学 |小高 |王老师 |70 |
|9 |数学 |小秦 |王老师 |80 |
|10 |数学 |小马 |王老师 |90 |
|11 |数学 |小朱 |王老师 |90 |
|12 |语文 |小高 |李老师 |70 |
|15 |语文 |小秦 |李老师 |70 |
|18 |语文 |小马 |李老师 |80 |
|21 |语文 |小朱 |李老师 |90 |
|24 |语文 |小钱 |李老师 |90 |select score,group_concat(student) from exam group by score;
|score |group_concat(student) |
-------------------------------------
|70 |小王,小赵,小高,小高,小秦 |
|80 |小红,小李,小孙,小秦,小马 |
|90 |小张,小钱,小马,小朱,小朱,小钱 |
29. all 和any
select * from table where column>all/any(value1, value2,......)
all(value1, value2,......)代表()中的所有值均进行前面的运算
any(value1, value2,......)代表()中的任意一个值进行前面的运算
四、内连接外连接自连接交叉连接
Remark:表先进行连接再进行select选择
建立如下所示表格:
ex1:
id label
1 A
2 B
3 C
ex2:
id label
1 D
2 E交叉连接:
select * from 表1,表2 or select * from 表1 join 表2
交叉连接的结果是表1和表2的所有行两两组合形成排列。
select * from ex1,ex2
id label id label
1 A 2 E
1 A 1 D
2 B 2 E
2 B 1 D
3 C 2 E
3 C 1 D
select * from ex1 join ex2
id label id label
1 A 2 E
1 A 1 D
2 B 2 E
2 B 1 D
3 C 2 E
3 C 1 D
select * from ex1 join ex2
where ex1.id=ex2.id
id label id label
1 A 1 D
2 B 2 E内连接:同交叉连接
select * from 表1 join 表2 on 条件
基于条件将表1和表2 两个表合并成为一个表,条件相同的部分记录形成新的一行。
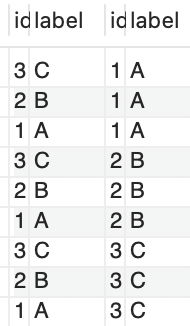
自连接:
select * from 表1 as 别名1 join 表1 as 别名2 on 条件
通过条件将两个相同的表进行交叉连接
select * from ex1 as a, ex1 as b
外连接分为两类:左连接和右连接
左连接:相当于先根据条件做内连接,然后补上左表的不匹配项
select * from ex1
left join ex2
on ex1.id=ex2.id
id label id label
1 A 1 D
2 B 2 E
3 C null null
右连接:相当于先根据条件做内连接,然后补上右表的不匹配项
select * from ex1
right join ex2
on ex1.id=ex2.id 等价于 using(id),列名相同时可以用using语句
id label id label
1 A 1 D
2 B 2 E
多表连接:
select * from 表1
join 表2 on 条件1
join 表3 on 条件2
join 表4 on 条件3
....不等式连接
在想要使用for循环的地方,可以通过表的自连接+不等式连接实现。
例1:摘自力扣的SQL中等难度题,需要用points表中的任意两个点连接形成的矩形面积,此时需要把id不想等的表格进行自连接。
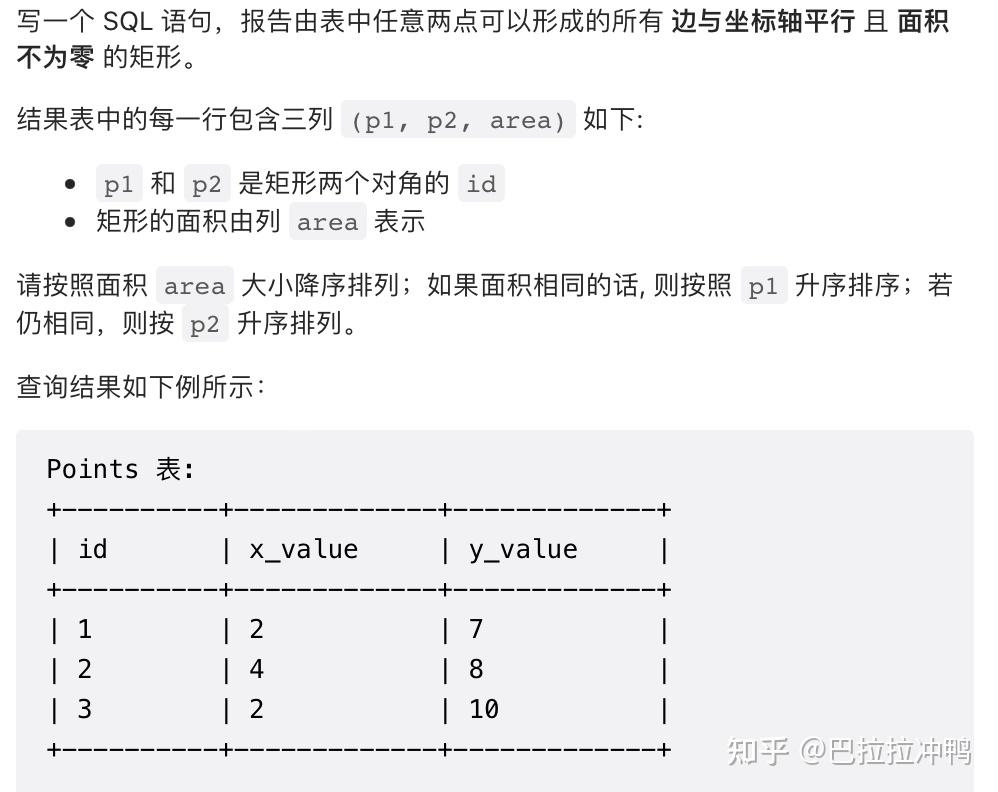

select p1.id as P1,p2.id as P2 ,abs(p1.x_value-p2.x_value)*abs(p2.y_value-p1.y_value) as AREA
from points as p1
join points as p2
on p1.id<p2.id --此处进行不等式连接
having AREA!=0
order by AREA desc,P1 asc,P2 asc例2:摘自力扣的中等难度题,需要查询表中连续出现至少三次的数

select distinct l1.num as ConsecutiveNums
from logs as l1
join logs as l2
on l1.id=l2.id-1
join logs as l3
on l2.id=l3.id-1
where l1.num=l2.num and l2.num=l3.num五、子查询
将select语句作为SQL其他语句的一部分的操作成为子查询。
#利用子查询进行选择
select * from table
where (select子句)
#利用子查询插入数据
insert into table1
select * from table2
#利用子查询更新数据
update table
set......
where (select 子句)
#利用子查询删除数据
delete from table
where (select 子句)
#相关子查询
select * from table as t
where column1>(
select * from table
where table.id=t.id
)
此时内部的子查询和外部相关,类似于for循环
#select 子查询
select col1,col2,(select 子句) from table
#from 子查询,会产生临时表,所以一定要别名。
select * from (select 子句) as 别名 where condition
六、SQL函数
| select avg(列名)from 表名 | 列平均 | select count(列名) from 表名
select count(distinct 列名) from 表名
select count(*) from 表名 | 求列元素个数,不包括NULL
count(*)返回表的行数 | | select first(列名) from 表名 | 返回列的第一个值 | | select last(列名) from 表名 | 返回列的最后一个值 | | select max(列名) from 表名 | 返回列的最大值,不包括NULL | | select min(列名) from 表名 | 返回列的最小值,不包括NULL | | select sum(列名) from 表名 | 返回列和 | | select 列名1,集成函数 from 表名 group by 列名1 | 按照列名1对表格进行分组,并在分组上运用集成函数 | | select 列名1,集成函数 from 表名 group by 列名1 having 条件 | having相当于where,不过where在group by作用前进行条件选择。
having 为group by作用后的表进行条件选择 | | select ucase(列名) from 表名 | 将列元素改成大写 | | select ucase(列名) from 表名 | 将列元素改成小写 | | select mid(列名,start,stop) from 表名 | 选择列元素从start到stop位置的字符,stop不写时默认取完。 | | select len(列名) from 表名 | 返回每一列的元素长度,空格也被计数。 | | select round(列名,N) from 表名 | 四舍五入并保留N为小数 | | now( ) | 返回当前的时间和日期 | | format(列名,“格式”) | 将该列元素转换成指定格式 | | select 列名 from 表名 limit start, N | 从start+1开始,取N行 |
数值函数
| round(a,N) | a四舍五入并保留N位小数 | | floor(a) | a向上取整 | | ceil(a) | a向下取整 | | abs(a) | 取a 的绝对值 | | rand() | 生成一个0-1之间的随机数 |
字符串函数
| length(str) | 返回str的字符个数 | | upper(str) | 将str全部大写 | | lower(str) | 将str全部小写 | | ltrim(str) | 去掉str的左空格 | | rtrim(str) | 去掉str的右空格 | | trim(str) | 去掉str的所有空格 | | left(str,N) | 返回str左边的N个字符 | | right(str,N) | 返回str右边的N个字符 | | substring(str,m,n) | 从str的第m个字符开始输出n个字符 | | locate(&#34;x&#34;,str) | 返回&#34;x&#34;在str中第一次出现的位置 | | replace(&#34;str&#34;,&#34;a&#34;,&#34;b&#34;) | 将str中的a替换成b | | concat(&#34;a&#34;,&#34;b&#34;) | 返回&#34;ab&#34; |
时间函数
| Now() | 返回当前日期和时间 | | curdate() | 返回当前日期 | | curtime() | 返回当前时间 | | year/month/day/hour/minute/second(now()) | 返回年/月/日/时/分/秒 | | dayname/monthname(now()) | 返回周几/几月 | | extract( year/month/day from now()) | 提取当前的年月日 |
NULL值处理函数
- ifnull(列名,&#34;str&#34;)----如果该列的某一行为NULL,则将其赋值为str。
select concat(first_name,&#34; &#34;,last_name),ifnull(phone,&#34;unkonwn&#34;)
from customers2. SELECT coalesce(列1,列2,...) as info FROM table1
当列1的某一行为NULL时,计算列2的这一行,一直到计算到第一个不为NULL的列,如果都为NULL,则返回NULL。
REMARK:
当数据库中无法匹配当前条件时,输出的数据行是为空而非null的。
可以使用聚合函数进行空值null值的转换,具体的聚合函数包括SUM/AVG/MAX/MIN
可以使用select语句进行转换,但空值应直接写在select中而非from中
limit语句无法出现新的null值
where和having同样无法出现新的null值
选择函数
1.if 函数
语法:if(exp, first, second)---如果exp满足则返回first表达式,否则返回second表达式。
select product_id,name,count(*) as orders,if(count(*)>1,&#34;Many times&#34;,&#34;Once&#34;)
from products
join order_items
using(product_id)
group by product_id,name2.case运算符
CASE
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
ELSE <表达式>
END (AS 别名)对于数据表中的每一条记录,CASE表达式会从第一个WHEN开始执行判断,如果返回结果为真(TRUE),那么就返回THEN中的表达式。CASE表达式的执行结束。
如果第一个WHEN执行结果不为真,那么就继续执行下一个WHEN,直到有一个为真,返回THEN中的表达式。CASE表达式的执行结束。
如果所有的WHEN都不为真,那么返回ELSE表达式的结果。执行结束。
格式化日期和时间
DATE_FORMAT(date,format)---date为日期,format为输出格式
日期和时间计算
SQL Date 函数
七、视图
create view 视图名 as (select子句)通过select子句创建视图后,我们可以把视图当作一个临时表格进行使用,大大简化SQL语言的书写。
with 视图名 as (select 子句)with子句定义完视图以后不用使用;,直接接后面的语句即可。
八、窗口函数
1.自定义标量函数
creat function 函数名(参数名 参数数据类型)
returns 数据类型
as
begin
函数体(一般是储存过程)
return 返回的参数名
end函数的调用方式和SQL的内置函数相同。
2.窗口函数
function (args) over (
[partition by partition_expression]#表示分组依据,对每一组会单独开一个窗口
[order by order_expression]#排序依据,可以实现组内排序
[frame]#相当于where 设定条件
)排序函数
| rank( ) | 出现相同值会排名并列,如1,2,2,4 | | dense_rank( ) | 出现相同值会排名并列但不会跳排名,如1,2,2,3 | | row_number( ) | 出现相同值排名也不会并列,如1,2,3,4 |
select score,
dense_rank() over (order by score desc) as &#34;rank&#34;
from scores |
|



 发表于 2023-3-11 22:11:00
发表于 2023-3-11 22:11:00