|
|
在我这里不会有太多枯燥的网上摘抄概念,全是理解,如有理解错误欢迎留言评论指正哦,当然我也会保证自己尽量不出现问题啦。
想要了解MVCC?那么你必须先对MySQL事务有概念
什么是事务?
当我们执行一些操作时,需要它们这些操作要么同时成功,要么同时失败.
比如银行转账,你转给我100块,最终要达到的目的是你的账户扣100,我的账户加100.最后你的账户扣了100,我得账户没加100,那你能干么?你能干我也不能干啊.
所以说事务就是为了保证数据的一致性
事务都有哪些属性?
事务通常具有四个属性:ACID
- 原子性(Atomicity):对数据的修改、要么全部成功 要么全部失败
- 一致性(Consistent) : 在事务开始和完成时,数据都必须保持一致状态,保持数据的完整性. (如下单功能:必须保持创建订单-扣减库存-加积分 这些操作同时成功或者同时失败保证数据前后的一致性)
- 隔离性(lsolation):数据库提供一定的隔离机制,保证事务不受外部并发操作影响"独立"环境执行
- 持久性(Durable):事务完成后,对数据的修改时永久性的,即便系统故障也不影响
这四个属性中哪个最重要?
我们上面已经说过了嘛,一致性啊,一致性是目的,其他都是为了实现目的的手段
并发事务带来的影响
我们都知道,当我们在操作一条数据时可能不是一个人 而是多个人操作,在数据库中就是多个事务同时对一条数据进行操作,那么这种情况下就会造成一些影响:
- 脏写(更新丢失):当两个或多个事务选择同一行,基于最初的源数据更新改行的话,最后更新的事务会覆盖其他事务所做的更新
- 脏读:读到了其他事务修改但是的未提交的数据
- 不可重复读(主要针对修改的数据):事务A读取到的数据在不同的时刻得出的结果不一致
- 幻读(主要针对新增的数据):事务A读取到了事务B新增的数据
表结构:

脏写举例:A,B两个事务开启,A,B查询id为1的数据中money=100,A对id为1的数据的money减50 然后修改并提交,B也对id为1的数据money减30 然后修改并提交,这个时候money原本应该变成20,但是实际变成了70(因为B事务中还是使用原数据100去修改的而不是使用A事务修改后的事务).
脏读举例:A,B两个事务开启,A,B查询id为1的数据中money=100,此时B事务修改money=50,那么此时A事务再次查询id为1的数据发现money变成50,然而此时B事务还没有提交.
不可重复读举例:A,B两个事务开启,事务A查询 id=1的数据 事务B对id=1的数据进行修改,那么事务A在事务B修改前后所得到的数据不同
幻读举例:A,B两个事务开启,A事务查询全表数据发现有三条id分别为1,2,3的数据,此时事务B向表中添加一条数据,A事务再次进行全表查询,发现查到了4条数据,发现和之前读取的数据不一致,就好像产生的幻觉,所以叫做幻读
四大隔离级别
为了解决并发事务带来的影响,所以数据库设计了四大隔离级别:

四大隔离级别及是否可能产生的问题
读未提交:可以读取其他事务未提交的数据
读已提交:只能读取其他事务已经提交的数据
可重复读(默认隔离级别):读取的数据在当前事务不能再被影响,始终是当前数据的值,解决了重复度的问题,但是在进行范围查找时,还是可以插入数据,所以可能会产生幻读.(其实这个隔离级别在一定程度上可以解决幻读,具体大家可以看下间隙锁,在这里就先不讲解它了,或许以后会有更新)
可串行化:事务最高的隔离级别,相当于把所有的事务穿成串一个一个的执行,所以不会出现问题,但是这种隔离级别,事务的执行非常消耗性能
数据库是如何保证事务的隔离性呢?
没错,就是通过加锁来实现事务的隔离性,但是频繁的加锁有很影响性能,读取修改也不方便,那么如何解决加锁后的性能问题? 当然是MVCC 多版本并发控制!它实现读取数据不用加锁,可以让读取数据同时修改。修改数据时同时可读取。
MVCC
MVCC(Multiversion Concurrency Control) 中文全称叫多版本并发控制,MySQL在可重复读隔离级别下 在同一个事务中多次执行的查询结果都相同,就算其他事务对当前数据进行多次修改也不会改变其查询结果。 这个就是使用MVCC多版本并发控制机制保证的,对一行数据的读和写操作默认是不会通过加锁互斥来保证隔离行,避免了频繁加锁互斥,而在串行化隔离级别中为了保证较高的隔离性是通过将所有操作添加锁互斥来实现的。
MySQL在RC(读已提交)和RR(可重复读)隔离级别下都实现了MVCC机制 (以下都以RC、RR替代)
undo日志版本链与Read View机制详解
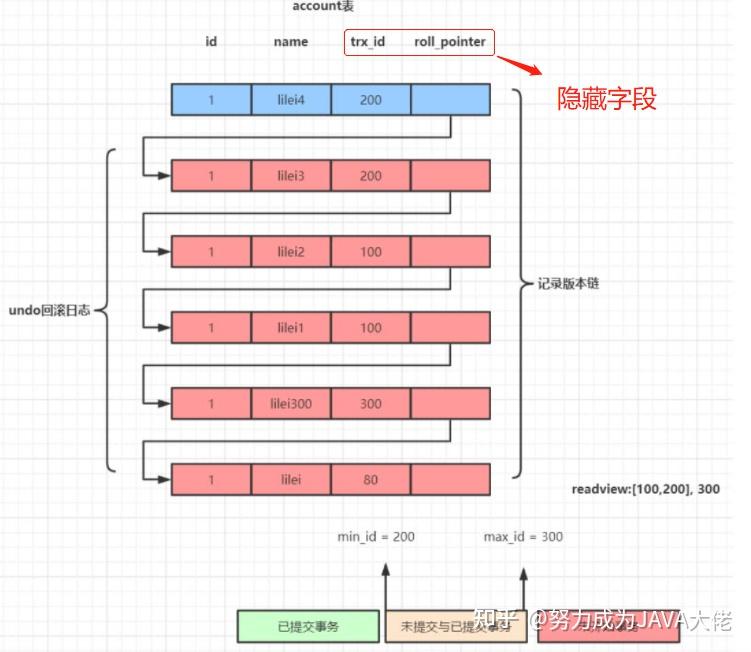
undo日志:一行数据被多个事务依次修改后,在每个事务修改完都会保存一条修改前的undo回滚日志,并且用两个隐藏字段trx_id(事务id)和roll_pointer(指针)将这些undo日志串联起来形成一个历史版本链(如上图)
事务id:事务每次开启时都会获取一个事务id,这个id是自增的,可以通过id大小来判断事务执行的先后顺序
roll_pointer(指针):用于指向上一条数据记录
在RR级别下,当事务开启,执行任何一条查询语句(不论你查询某个字段)时都会生成当前事务的一致性视图read_view,该视图在当前事务结束之前都不会发生变化(RC级别下是每执行一条sql都会生成一个新的read-view视图),这个视图是由执行查询时所有未提交的事务id数组(数组中最小的id为上图中表示的min_id)和已创建的最大事务id组成(max_id),事务中任何sql查询结果都需要从对应的版本链里的最新数据开始逐条跟read_view进行比对从而得到最终的快照结果(如上图中最新一条数据为蓝色的一条根据指针逐一向下比对,比对方式在下方)
版本链比对规则:
- 如果 row 的 trx id 落在绿色部分( trx id<min id),表示这个版本是已提交的事务生成的,这个数据是可见的;
- 如果 row 的 trx id 落在绿色部分( trx id<min id),表示这个版本是已提交的事务生成的,这个数据是可见的;
- 如果row 的 trx id 落在红色部分( trx id>max id ),表示这个版本是由将来启动的事务生成的,是不可见的(若row 的 trx id 就是当前自己的事务是可见的);
- 若row 的 trx id 不在视图数组中,表示这个版本是已经提交了的事务生成的,可见。
- 如果 row 的 trx id 落在黄色部分(min id <=trx id<= max id),那就包括两种情况
- 若 row 的 trx id 在视图数组中,表示这个版本是由还没提交的事务生成的,不可见
- 若 row 的 trx id 就是当前自己的事务是可见的;
- 比对时需要注意的点:
- 版本链:未提交事务id数组+已创建的最大事务id数组(不论这个事务是否提交) 如果最大事务id的事务未提交的话 版本链应该为: [min_id,最大事务id]+最大事务id
- 要根据指针指向的记录依次比对
举例:

此时红色指针处生成的readview应该是:[100,300],400,查询到的结果应该是wangwu,如果没有当前节点修改,那么查询到的结果应该是zhaoliu,生成的版本链应该如下图:
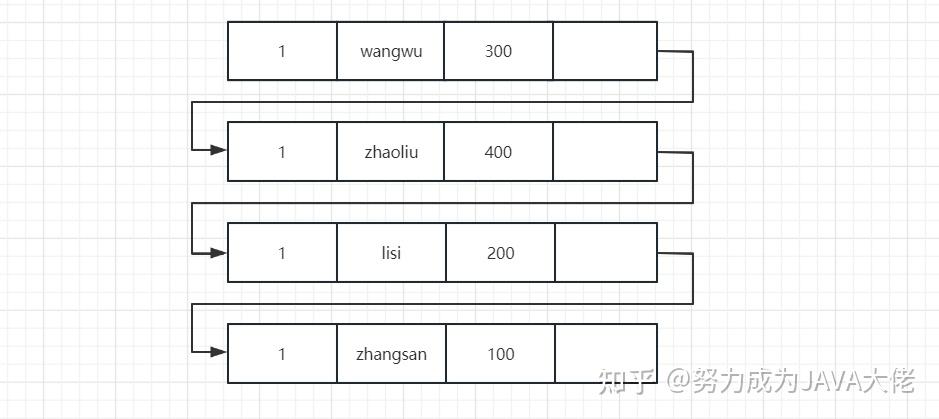
MVCC机制的实现就是通过read-view机制与undo版本链比对机制,使得不同的事务会根据数据版本链对比规则读取同一条数据在版本链上的不同版本数据。 |
|



 发表于 2023-3-5 18:10:57
发表于 2023-3-5 18:10:57